
A couple of years ago, I started serving my blog posts as plain text. Add .txt to the end of any URl and get a deliciously lo-fi, UTF-8, mono[chrome|space] alternative. Here's this post in plain text - https://shkspr.mobi/blog/2025/12/a-small-collection-of-text-only-websites.txt Obviously a webpage without links is like a fish without a bicycle, but the joy of the web is that there are no…
Continue reading →

By and large, the English language doesn't use diacritical marks. Even our loanwords are stripped of them; we drink in a cafe rather than the more pretentious café. This has a consequence for HTML and, by extension, eBooks. As a quick primer, modern computing gives us two main ways of displaying a letter with an accent. The first is simple - encode every single accented letter as a separate …
Continue reading →

I was noodling around in PHP the other day and discovered that this works: <?php $🍞 = "bread"; echo "Some delicious " . $🍞; I mean, there's no reason why it shouldn't work. An emoji is just a Unicode character (OK, not just a character - but we'll get on to that), so it should be fine to use anywhere. Emoji work perfectly well as function names: function 😺🐶() { echo "catdog!"; } 😺🐶(); De…
Continue reading →

We live in the future now. It is OK to use Unicode everywhere. It seems bizarre to me that modern Internet services sometimes "forget" that there's a world outside the Anglosphere. Some people have the temerity to speak foreign languages! And some of those languages have accents on their letters!! Even worse, some don't use English letters at all!!! A decade ago, I was miffed that GitHub only…
Continue reading →

OK, first off, you have to read this amazing judgement about whether Walker's Sensations Poppadoms count as a potato-based snack for VAT purposes. Like most judgements, it is written in fairly plain and accessible language. The arguments are easy to follow and it even manages to throw in a little humour. But if you read closely, you'll see there are a few instances where an errant question-mark …
Continue reading →

How would you read this sentence out aloud? "In Hamlet, Act Ⅳ, Scene Ⅸ..." Most people with a grasp of the interplay between English and Latin would say "In Hamlet, Act four, scene nine". And they'd be right! But screen-readers - computer programs which convert text into speech - often get this wrong. Why? Well, because I didn't just type "Uppercase Letter i, Uppercase Letter v". Instead, I u…
Continue reading →

Why do most programming languages use the / character when we have a perfectly good ÷ symbol? Similarly, why use != instead of ≠? Or => rather than →? The obvious answer is that the humble keyboard usually only has around 100 keys - and most humans have a hard time remembering where thousands of alternate characters are. Some programming fonts attempt to get around this with ligatures. That all…
Continue reading →

Originally posted as part of HTML Hell's advent calendar. While browsing Mastodon late one night, I came across this excellent blog post called HTML is all you need to make a website. It describes a few websites which are pure HTML. No CSS and no JS. And I thought… do you even need HTML to make a website? A few hours later, I launched the NO-HT.ML website. Proving, once and for all, that you d…
Continue reading →

You know how it is, you buy one silly domain name and then you get an idea for loads more! A few weeks ago, I got https://⏻.ga/ - I think I'm the first person to get a domain name which uses a glyph from the Miscellaneous Symbols Unicode block. How exciting! And that got me wondering… what other abuses of the Punycode algorithm can I whack into DNS? Well, here's some I whipped up using FreeNom …
Continue reading →

Like all good geeks, I have far too many domain names that I acquired for interesting projects which never took off. My latest is a bit different though. https://⏻.ga/🔗 That's "Unicode Power Symbol Dot Gabon". Because why not. Regular readers will know that I helped get ⏻ and several power symbols into Unicode. When I do talks about this, I usually refer to them as Emoji because, to most peo…
Continue reading →

I present to you, dear reader, a spiral containing every Unicode 14 character in the GNU Unifont. Starting at the centre with the control characters, spiralling clockwise through the remnants of ASCII, and out across the entirety of the Basic Multi Lingual Plane. Then beyond into the esoteric mysteries of the Higher Planes. Zoom in for the massiveness. It's a 10,000x10,000px image. Because…
Continue reading →
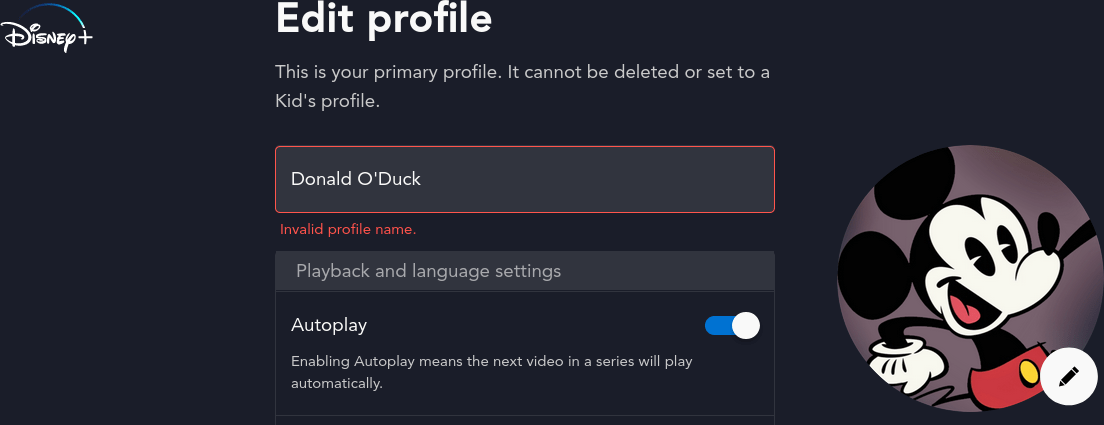
Because I'm genetically pre-disposed to watch every piece of Star Wars content ever created, I signed up for a free trial of Disney's newest streaming service. As part of onboarding, it asked me to create a profile name. This is typically done so that multi-user households can have separate profiles and preferences. Mum doesn't have her princess stories disrupting Dad's suggestions. And Junior…
Continue reading →