
Yes, I know the cliché that bloggers are always blogging about blogging! I like semantics. It tickles that part of my delicious meaty brain that longs for structure. Semantics are good for computers and humans. Computers can easily understand the structure of the data, humans can use tools like screen-readers to extract the data they're interested in. In HTML, there are three main ways to …
Continue reading →

I like using microdata within my HTML to provide semantic metadata. One of my pages had this scrap of code on it: <time itemprop="datePublished" itemscope datetime="2025-06-09T11:27:06+01:00">9 June 2025 11:27</time> The Google Search Console was throwing this error: I was fairly sure that was a valid ISO 8601 string. It certainly matched the description in the Google…
Continue reading →

I recently read a brilliantly provocative blog post called "This website has no class". In it, Adam Stoddard makes the case that you might not need CSS classes on a modern website: I think constraints lead to interesting, creative solutions […]. Instead of relying on built in elements a bit more, I decided to banish classes from my website completely. Long time readers will know that I'm a big f…
Continue reading →
My name is Terence(/ˈtɛɹəns) Eden(ˈiːdən/). Modern HTML allows the user to use <ruby> to annotate text. This is usually used for furigana - which allows pronunciation to be placed above words. For example: "シン・ゴジラ (Shin Godzilla)" shows you how to pronounce both words if you are unfamiliar with kanji. The text can be any language or use any characters. In Japanese, it is quite often used to sh…
Continue reading →

I'm a little bit obsessed with the idea of Semantic markup. I want the words that I write to be understood my humans and machines. Imagine this piece of code: print( "Hello, world!" ) Is that code example written in Python? C++? Basic? Go? Perhaps you're familiar enough with every programming language to tell - but most people aren't. Wouldn't it be nice to give an indication of what…
Continue reading →

One of the (many) problems with AI is that training data usually needs to come from "natural" sources. If you want to emulate human-written text, you need to train something on human-written text. But with the proliferation of cheap and fast AI tools, it is likely that training data will unwillingly become contaminated with AI-written text. In order to prevent the "Habsburg Jaw" effect, I…
Continue reading →

I'm a big fan of machine-readable metadata. It's useful for programs which need to extract information from messy and complicated websites. It's always surprising where it turns up. For example, take this post of mine on LinkedIn. If you view the source, you'll see this scrap of linked data: <script type="application/ld+json"> { "@context":…
Continue reading →
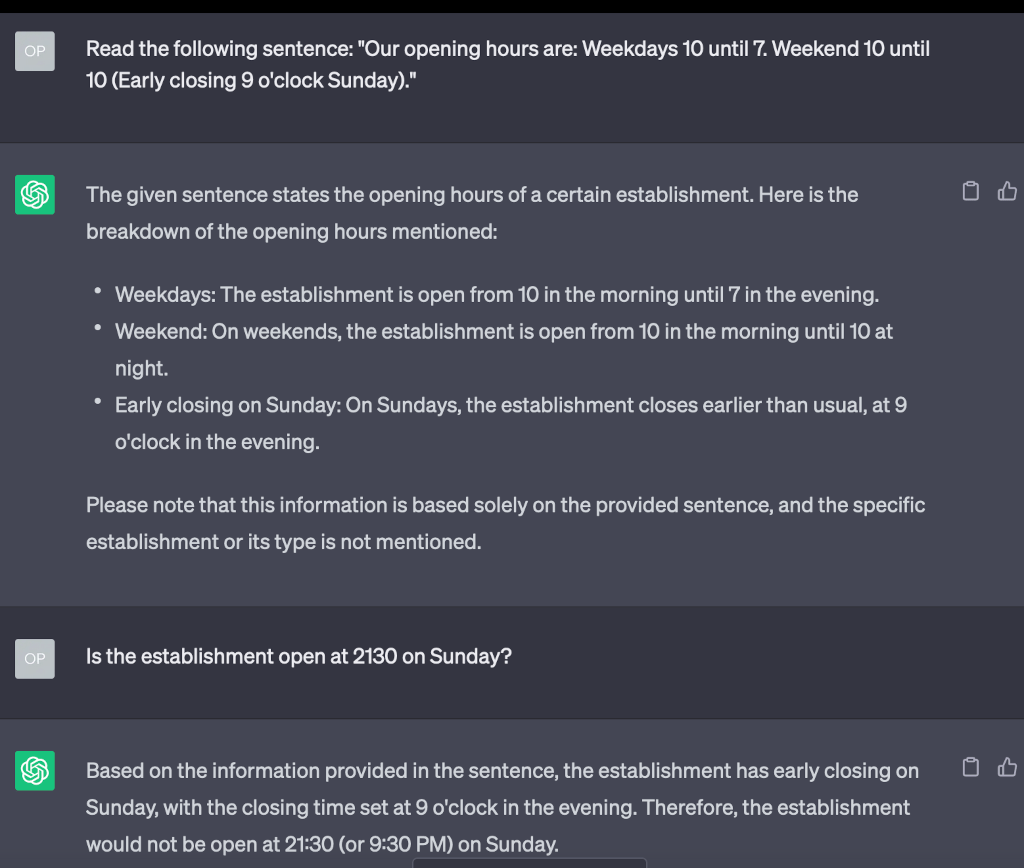
If you hang around with computerists long enough, they start talking about the Semantic Web. If you can represent human knowledge in a way that's easy for computers to understand it will be transformative for information processing. But computers, traditionally, haven't been very good at parsing ambiguous human text. Suppose you saw this text written for a human: Our opening hours are:…
Continue reading →
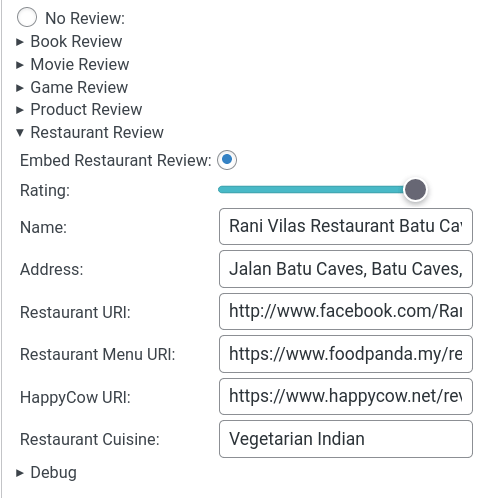
I've started adding Restaurant Reviews to this blog - with delicious semantic metadata. Previously I'd been posting all my reviews to HappyCow. It's a great site for finding veggie-friendly food around the worlds, but I wanted to experiment more with the IndieWeb idea of POSSE. So now I can Post on my Own Site and Syndicate Elsewhere. The Schema.org representation of a Restaurant is pretty…
Continue reading →

As regular readers will know, I love adding Semantic things to my blog. The standard WordPress comments HTML isn't very semantic - so I thought I'd change that. Here's some code which you can add to your blog's theme - an an explanation of how it works. The aim is to end up with some HTML which looks like this (edited for brevity): <li itemscope itemtype="https://schema.org/Comment"…
Continue reading →

Inspired by John Hoare at the Dirty Feed blog - I've asked the British Library to assign my blog an International Standard Serial Number (ISSN). An ISSN is an 8-digit code used to identify newspapers, journals, magazines and periodicals of all kinds and on all media–print and electronic. Why? Shut up. OK. It turns out that lots of people cite my blog in academic papers - so I wanted to make …
Continue reading →

Academic citations are hard. One of the joys of the Digital Object Identifier System (DOI) is that every academic paper gets a unique reference - like: 10.34053/artivate.8.2.2. As well as always leading you to a URl of the paper, a DOI also provides lots of metadata. Things like author, publisher, ORCID, year of publication etc. I've built a simple website that turns any DOI into a semantic…
Continue reading →