I found a curious little bug and I'm interested in who you think should take responsibility for it.
My mobile network provider sent me this message:
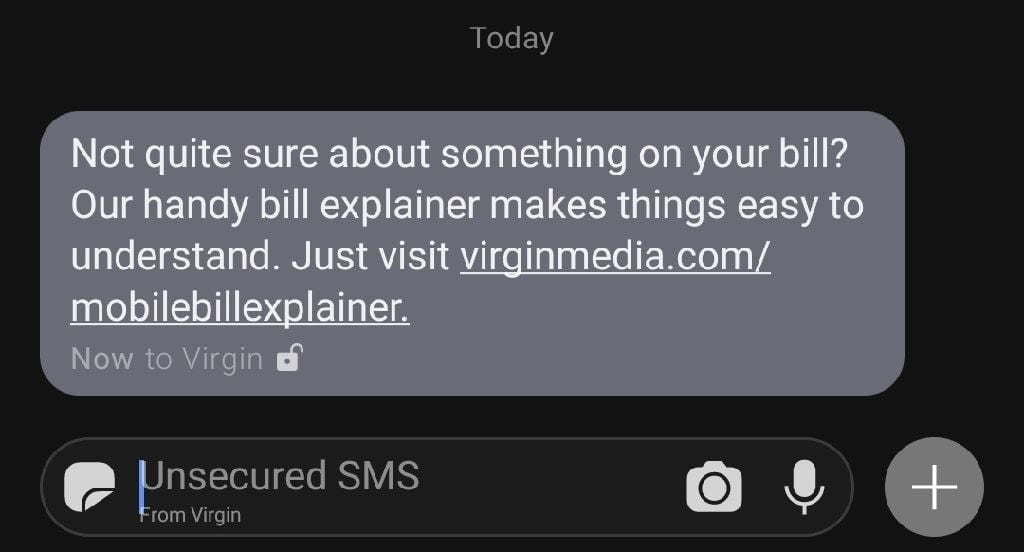
I clicked on the link, and got this error message from their website:

The error is caused by the trailing full-stop.

Remove the full-stop and the page loads.
There are four potential culprits here...
Virgin Media's Web Team
Should their website handle stray punctuation at the end of a URl?
Most webservers can be configured to take users to the page the server thinks they intended to go. This is mostly useful behaviour, but occasionally falls foul of the common DWIM (Do What I Mean) problems.
Even if the web team don't redirect, they should notice the elevated number of 404 errors and investigate the cause of it.
Whisper Systems' Signal App
My SMS app should parse URls without trailing punctuation. It is rare that a URl will deliberately end with a punctuation mark. This issue has been raised with the team before.
Apparently, according to the developers, this is a problem with Android's native library
Android's URl Parsing Library
The same question as above. Android has a built in Web URl regular expression. There are reports that it is inconsistent in the way it parses URls.
A URl which ends with a full-stop is valid. There is a semantic difference between /page and /page. or /?id=a and /?id=a.
But the RFC doesn't take into account how humans actually communicate.
If I send a message saying "visit example.com/go, then example.com/next!" do I really mean for the , and ! to be part of the path?
I can't find any evidence of Google testing this feature with users, nor a test suite to show people what URls are and are not matched.
It appears that the library only includes the punctuation if it is the last character in a string.
Virgin Media's Marketing Team
These are who I think the real villains. Software has bugs. Part of any communications strategy is to test your messages to see whether they work. Not just as calls-to-action, but whether they actually work.
In this case, Virgin should have tested their message on a range of handsets and popular SMS apps. If they had tested the end-to-end journey on Android, this wouldn't have happened.
What next
There's no point me asking Virgin to fix this. They have dreadful customer service and seem content to have a crappy user experience.
It's not Signal's fault that Android's parsing is buggy. Both Signal and Telegram greedily gobble up the . and treat it as part of the link. Interestingly, WhatsApp doesn't. I assume WhatsApp uses its own library.
So, I've raise a bug with Android where - no doubt - it will languish untouched for the next hundred years.
15 thoughts on “Whose bug is it anyway?”
Virgin Media own the customer and their experience - so they should 'fix' it - whether that means changing some code, choosing a different component, writing different copy, redirecting server-side or something else.
| Reply to original comment on twitter.com
I wonder how easy it would be to update the spec for URLs to disallow punctuation at the end of a URL?!
But I would definitely blame Virgin Media for not testing their comms
| Reply to original comment on twitter.com
gberger
Extremely hard. It would break backward compatibility.
Putting links in SMS messages is just a terrible idea anyway.
We have to stop teaching users that it's okay to click on links sent to them in an SMS - it's so exploitable phishing attacks.
The SMS could very easily have read "Not quite sure about something on your bill? Search for the "Virgin Media Bill Explainer" or an alternative call to action ("Check your account page for our new Mobile Bill explainer".
Just like unsolicited phone calls from your "bank" asking for personal information, SMS texts with links in them should be treated as spam/phishing. The only reason these are effective means of attack is that we keep teaching users that these are normal behaviours.
That is impractical and irresponsible. Asking users to take multiple steps doesn't work. That's why we use links rather than asking people to search for things. Take a look at the adverts on Google results when you search for "company name login" - you'll find lots of spam and scams. At least the VM texts use the full URl rather than going through a shortner.
Google Ads are a separate and equally frustrating issue (which Google have had lots of opportunity to fix).
The problem is that these links are easily maliciously disguised as something else (eg. using different but similar looking unicode characters in a URL).
Authorised Push Payment and impersonation fraud in this country rose around 50% from last year (Source: UK Finance). A fair amount of that is through "smishing" (SMS phishing). We need to do better at not training users to click on things we know can be easily manipulated.
No, it's the same issue. You can't punt the problem to someone else, you have to look at it holistically.
Fair point. But we should look at the whole system then.
I agree, my suggestion that people should just search something wasn't well thought out. But neither is just sending them a URL to click on. And phishing is a big, expensive and contentious issue (in banking at least) right now.
Number spoofing is another rabbit hole we could talk about. Do-not-originate doesn't actually fix the problem, for example.
At lot of time has been invested in blaming users, when actual the systems we have designed are setting them up to fail.
Dave Cridland
I don't think that not using URLs is a sensible choice - that essentially moves the problem onto Google, and Google Bombs have been a fine way of confusing that.
The RFCs do, actually, try to tell people not to just put URIs into text "unadorned" - you're meant to wrap them in angle brackets, for example - but in practise this is understandably ignored. See https://tools.ietf.org/html/rfc3986#appendix-C - or should that be https://tools.ietf.org/html/rfc3986#appendix-C?
But yes, whole-heartedly agree that heuristic parsing algorithms are tricky, and that marketing teams need to test their marketing is functional.
Syed
Clearly the problem here was caused by the full stop, it should stop passing the buck and take responsibility.
Whose bug is it anyway?Link: shkspr.mobi/blog/2020/07/w…Comments: news.ycombinator.com/item?id=239263…
| Reply to original comment on twitter.com
Alex Wells
So, in the world I work, I build systems for (as an example) marketing teams to submit these types of messages, have them approved by an approval mechanism, and then deployed in some fashion.
I suggest then, that there is a fifth culprit. The system that is in place (assuming of course that there is one), upon which the marketing team input their suggested text, should check that any URLs in the body of the text resolve properly.
Yes, testing from the Marketing team would have been good, but we all know that even development teams have problems in this area when it’s manual. I think we could break the actors down in a different way:
1.) Content creator (Marketing team) 2.) Content management system/service solution 3.) Release management 4.) Deployment/delivery 5.) Consuming applications 6.) Webservers receiving the URL from the consumer app
I think that the problem is at points 1, 2 and 3 of this process. 4, 5 and 6 have functioned perfectly, and putting sticking tape in place would only introduce technical debt in those areas.
You can blame the marketing team, but that gets you nowhere, there is no solution to be found other than saying “please don’t do this”.
You can blame the release process (testing etc.) absolutely, and more testing would have been good, but in pure release terms, the content that was asked to be deployed was deployed properly.
So here (and I rarely say this personally) technology could have prevented this. It is technology (VM’s webservers) that has stipulated that the URL must be of a certain form, so Virgin Media’s own technology (the CMS) should have ensured that the content put out by the marketing team matched up to their own standards expected by their webservers.
A year later and I don't think Google have fixed this Android bug.Yay open source…
| Reply to original comment on twitter.com
Tony Hoyle
It's not uncommon in development to have a bug that is caused by something downstream. Replying 'not my bug' is fine internally but bad professionally because it's still on you to find a workaround - upstream (users, customers) don't give a flying f..k who's bug it is.
So I'd put at least partly on Signal here for not implementing a (temporary, we hope) workaround and reporting the bug to google.
Also VM for having inadequate testing. I bet they loaded it on iOS and called it good..
"Virgin should have tested their message on a range of handsets and popular SMS apps"
...or just not put punctuation after a URL. Personally I've trained myself to simply avoid any characters around a URL in any kind of comms, whether it's full stops, commas, quotes or brackets. Perhaps this caution comes from emailing, where you have to assume that any number of linkifying parsers, broken or otherwise, will do their best to mangle your message. SMS is the same. The people at Virgin Media who compose SMS messages for a living should have thought about adding the full stop and immediately realised it's not worth it.