About a million years ago, I was discussing the FOAF (Friend of a Friend) ontology with its early proponents. It allowed you to define a machine-readable semantic relationship like "Alice is married to Bill" and "Bill is Carol's child" and "Carol works for David". That sort of thing.
At the time, all the FOAF relationships were defined in terms of positive sentiment. There wasn't (and still isn't) a FOAF representation for "divorced" or "estranged" or "fired by". I thought this was a failing. I understand why we all might want to play nice on the Internet. But sometimes it is useful to know about "negative" relationships.
For example, I want to organise a seating plan for my wedding - it's helpful to know that Alice and Bill divorced and can't be on the same table, Carol doesn't talk to David. Bill is in a relationship with David and wants to keep it secret. Ellen would like to know Alice better. That sort of thing.
More modern versions of FOAF have properties like enemyOf and wouldLikeToKnow. Which I think makes a great deal of sense.
And so we come to Academic Citations.
Using Google Scholar (or any other knowledge graph) I can find just about any academic paper. More importantly, it lets me see every paper which references that paper.

Great! I can see if something has been cited lots of times, or very few times. That gives me a weak signal about its "importance".
But it tells me nothing about the sentiment of those citations.
Suppose I've just read (Smith, 2015) and I want to know whether the consensus is that the paper is a work of genius or absolute horseshit. What are my options? I can find all the citations of it, then manually read each one to determine whether the author thinks Smith is off their rocker or not.
Wikidata has support for this. The Cites Work property can have roles like "objection" and "endorsement"
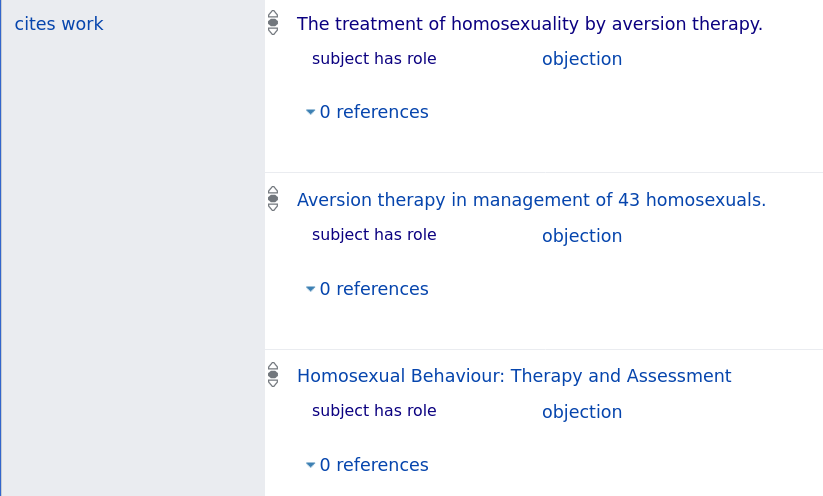
This means, in theory, someone could build a knowledge graph which says "Smith's argument rests on Jones' paper, but Xi's paper and Zhang's paper both object to Jones. Hook disagrees with Zhang's analysis, but these 500 papers disagree with Hook."
Why is this important
One problem that modern social media has is that its algorithms have no knowledge of sentiment. Whether you share a cute kitten video to make your friends smile or share a hateful message by a bigot in order to whip up a frenzy against them - the algorithm sees the same signal; +1.
This means the outrage economy grows quickly. All "shares" are seen as positive sentiment. The algorithm sees lots of shares, interprets that a positive signal, and then further promotes the content - or similar content. There is very little way that a social network can filter content by "agrees with" or "disagrees with".
Things like Facebook attempt to map sentiment with a series of emoji.

In theory, you could tell Facebook not to show you posts which have more than 10% of anger reactions. Or only show you posts with positive sentiment. I say "in theory" because Facebook profits off your rage, so has no interest in helping you moderate your emotions.
Popping back to academia for a moment. I recently read a paper that I disagreed with. I wanted to know if I was alone in my objection. This is currently no way for me to find all the citations which also disagree with the paper.
Why this will never happen
The first thing that stops this is that it is a lot of extra work for a human to perform. With hundreds of citations per paper, it would be a massive burden to categorise every single paper mentioned in passing. Most academics can't even be bothered to write alt-text for their images, so any extra labour is likely to be resisted.
The second problem is that sentiment is hard! Can it be boiled down to just "agrees with" and "disagrees with"? What about "Agrees with methodology but not conclusion" or "Disagrees with some definitions but supports others"? There are hundreds of different sentiments. Even just positive and negative probably need degrees of strength associated with them.
In the glorious future where DEEP AI and MACHINE CLEVERNESS rules, it might be possible for a computer to read an academic paper and determine whether it concurs with the papers referenced therein.
Perhaps we need an army of (paid?) dogsbodies to manually go through every paper ever published and assess the sentiment behind each citation?
But, for now, we have to make do with weak signals and uncertain sentiment.
4 thoughts on “Why is there no Semantic Ontology of Sentiment in Academic Citations?”
Why Is There No Semantic Ontology of Sentiment in Academic Citations?Link: shkspr.mobi/blog/2022/07/w…Comments: news.ycombinator.com/item?id=320449…
| Reply to original comment on twitter.com
Jay Patel
You may like Scite.ai (via Josh Nicholson), an AI startup working on exactly this problem.
Also, I have (as an academic) been toying with similar ideas.
A few papers in the Information Science field may be worth examining here.
@edent
Any specific papers you'd reccomend?
I wrote about this eight years ago on SV-POW!: svpow.com/2014/03/25/we-…
Turns out there is one: ucl.ac.uk/library/resear…
| Reply to original comment on twitter.com
More comments on Mastodon.