
Unicode contains a range of symbols which don't get much use. For example, there are separate symbols for TradeMark - ™, Service Mark - ℠, and Prescriptions - ℞. Nestling among the "Letterlike Symbols" are two curious entries. Both of these are single characters: Telephone symbol - ℡ Numero Sign - № What's interesting is both .tel and .no are Top-Level-Domains (TLD) on the Domain Name System (DNS). So my contact site - https://edent.tel/ - can be written as - https://edent.℡/ And the Nor…
Continue reading →
I have been receiving letters from a dear friend by the name of Ophiuchus. He has been researching some curious anomalies in the Unicode Standard. While I cannot vouch for all he has written, I thought it worth presenting his discoveries to you. My friend, I bring you a curiosity! I have been engaged in a most frustrating task. That is, trying to decipher the ancient history of our friends at The Consortium. They have refused me access to their archives, but I have bribed a friendly…
Continue reading →
Google is a company with nearly unlimited resources. It often chooses to use its power for the greater good of the Internet. Creating amazing projects like digitizing every printed book, bringing Internet access via high-altitude balloons, and offering high-quality language translation. And sometimes it just gets bored and abandons them. Google Noto is such a project. It is an attempt to create beautiful fonts for every single human language. It promises No ToFu - no more blank boxes where a…
Continue reading →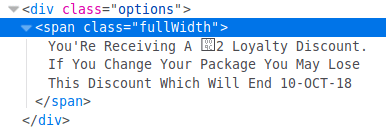
More adventures with Unicode. I logged in to my Virgin Media account to see when my promotional discount would end. Here's what their billing PDF said. Let'S Ignore The Weird Capitalisation Virgin'S System Uses. What's that  doing there? Their website says: No  symbol, but also no £ sign. Ah, but let's look at the underlying code. What's that weird character? It is the control character string terminator, of course... Well, my discount is nearly finished, so I asked them for a la…
Continue reading →
A short meander through some of the more obscure miscellany within Unicode. Languages hang around far longer than there are native speakers, and symbols get reused and repurposed (🍆). Here are some of the delightfully old-fashioned symbols hidden in your thoroughly modern smartphone. Tapes Long before solid-state drives, we used to record data on long thin strips of magnetic tape. 🖭 📼 I'm sure there's a hipster somewhere who only listens to Kraftwerk on C90 cassettes, and claims that the ima…
Continue reading →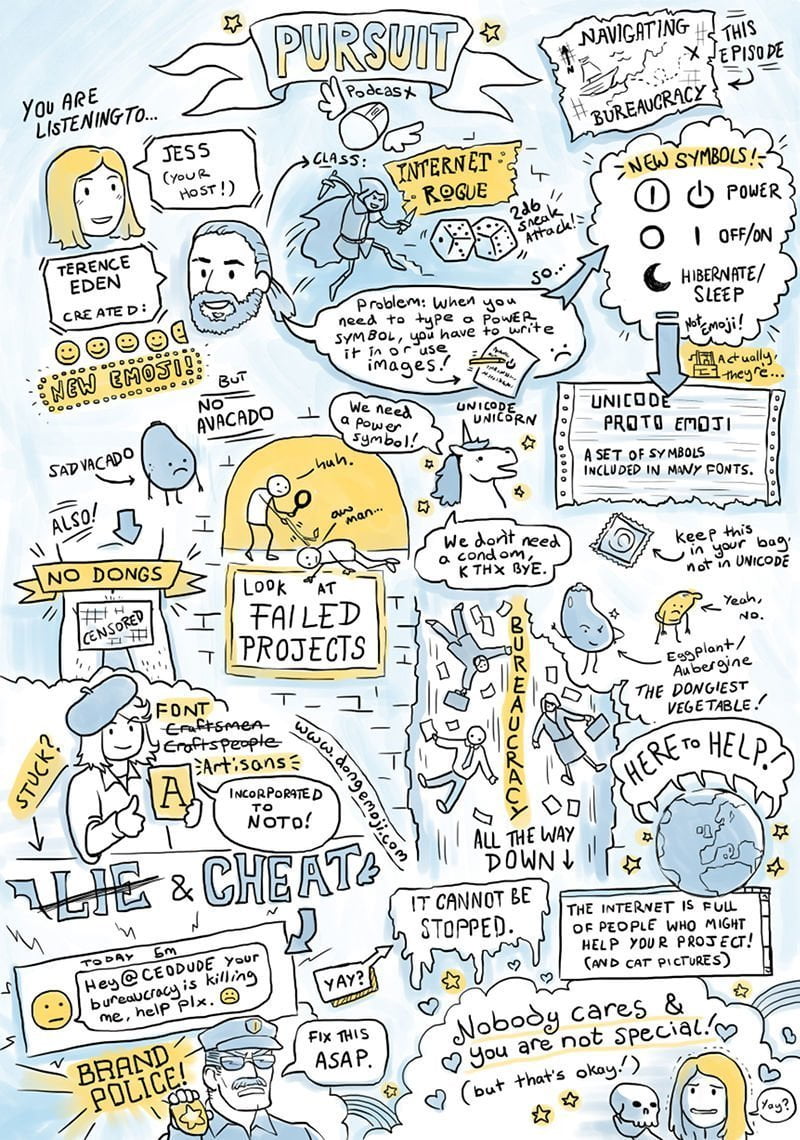
The inimitable Jess Rose interviewed me for her Pursuit Podcast - talking about the Unicode Power Symbol proposal. We talked about how to subvert bureaucracy, building a team of supporters, adding new stuff to Unicode, and recognising that you're a background character in most people's lives. Bit of a ramble, but jolly good fun. Sketchnotes by the exquisitely talented Kate Holden. Find out more about Jess and subscribe to Pursuit Podcast and leave a nice review. …
Continue reading →
In the last couple of months, I've been seeing the ú symbol on British receipts. Why? 1963 - ASCII In the beginning* was ASCII. A standard way for computers to exchange text. ASCII was originally designed with 7 bits - that means 128 possible symbols. That ought to be enough for everyone, right? Wrong! ASCII is the American Code for Information Interchange. It contains a $ symbol, but nothing for other currencies. That's a problem because we don't all speak American. *ASCII has its …
Continue reading →
This is a blog post about user interfaces. I was wandering along the beach one day, when I noticed some clever chap had drawn some arrows in the sand. Can you guess where they led? The more astute of you will have realised that these are not human drawn arrows. They are, of course, footprints left by birds. A bird's foot is a "backwards" arrow. The apex points to the bird's rear. It is conceivable that had birds evolved greater intelligence and developed a writing system then their → …
Continue reading →
Imagine you have a series of number you wish to sort. Sorting is a well known computer science problem - generally speaking you compare one value to the next and then move the item either up or down a list. With "English" characters, that's fairly easy. When a computer sees the character 1 it's really seeing the Unicode character U+0031. When it sees 2 it's really seeing the character U+0032 and so on. The Arabic numbers we use (0 - 9) have an identical ordering in Unicode. This makes it…
Continue reading →
We all know what an email address looks like and how to validate them, right? A few years ago I got the Chinese domain name 莎士比亚.org. You can browse to it, link to it, and send email to it. Or can you? When I tried two years ago, none of the major email providers supported sending to non-ASCII email addresses. Today, I tried again with six of the big "Western" webmail providers. How did they do? Show Me The Data! I tested by trying to send an email to test@莎士比亚.org and the Punycode repre…
Continue reading →
When is a string not a string? When it's a series of control characters! Not a particularly funny riddle, but one I've been wrestling with recently. Imagine we want to write a program which displays a Twitter user's name. Not their @ handle, but their "real" name. For example, instead of @POTUS, display "President Obama". Easy, right? Not quite. What happens when a user is named "️"? Normally, we'd just say if (null == $name) { ...Do Stuff... } Ah! But that's not an empty string, i…
Continue reading →
New tech site Gadgette has a great article on how to type Emoji on Mac and Windows - but they (understandably) didn't cover Ubuntu. So here I am to show you how. Get The Fonts If your computer doesn't have the requite font, install the latest version of Symbola. Simply open up the .zip file, double click on the .ttf font, then choose "Install". Find The Character You almost certainly have the GNU CharMap app installed. If not, run apt-get install gucharmap. You'll find it in…
Continue reading →