
My name is Terence(/ˈtɛɹəns) Eden(ˈiːdən/). Modern HTML allows the user to use <ruby> to annotate text. This is usually used for furigana - which allows pronunciation to be placed above words. For example: "シン・ゴジラ (Shin Godzilla)" shows you how to pronounce both words if you are unfamiliar with kanji. The text can be any language or use any characters. In Japanese, it is quite often used to show phonetic pronunciation using hiragana. Because English is a composite language, it isn't always …
Continue reading →
I'm a little bit obsessed with the idea of Semantic markup. I want the words that I write to be understood my humans and machines. Imagine this piece of code: print( "Hello, world!" ) Is that code example written in Python? C++? Basic? Go? Perhaps you're familiar enough with every programming language to tell - but most people aren't. Wouldn't it be nice to give an indication of what programming language is used in an example? Here's how we might represent it in HTML: <pre> <code> …
Continue reading →
One of the (many) problems with AI is that training data usually needs to come from "natural" sources. If you want to emulate human-written text, you need to train something on human-written text. But with the proliferation of cheap and fast AI tools, it is likely that training data will unwillingly become contaminated with AI-written text. In order to prevent the "Habsburg Jaw" effect, I think it would be helpful if publishers could semantically indicate that a work was written by AI. In…
Continue reading →
I'm a big fan of machine-readable metadata. It's useful for programs which need to extract information from messy and complicated websites. It's always surprising where it turns up. For example, take this post of mine on LinkedIn. If you view the source, you'll see this scrap of linked data: <script type="application/ld+json"> { "@context": "http://schema.org", "@type": "SocialMediaPosting", "@id":…
Continue reading →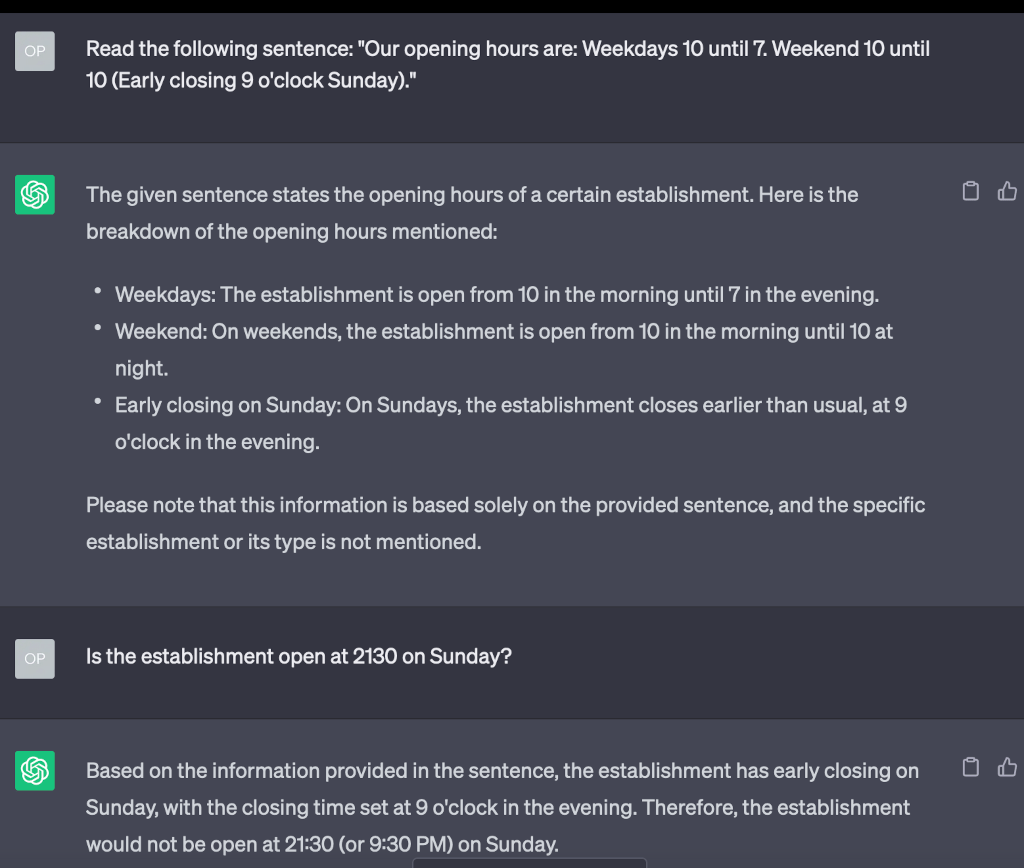
If you hang around with computerists long enough, they start talking about the Semantic Web. If you can represent human knowledge in a way that's easy for computers to understand it will be transformative for information processing. But computers, traditionally, haven't been very good at parsing ambiguous human text. Suppose you saw this text written for a human: Our opening hours are: Weekdays 10 until 7. Weekend 10 until 10 (Early closing 9 o'clock Sunday). Not the most straightforward…
Continue reading →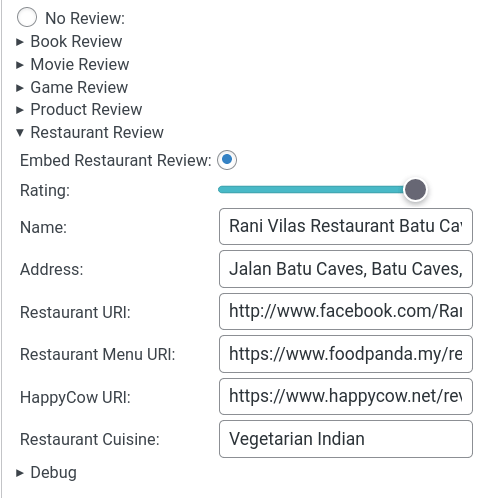
I've started adding Restaurant Reviews to this blog - with delicious semantic metadata. Previously I'd been posting all my reviews to HappyCow. It's a great site for finding veggie-friendly food around the worlds, but I wanted to experiment more with the IndieWeb idea of POSSE. So now I can Post on my Own Site and Syndicate Elsewhere. The Schema.org representation of a Restaurant is pretty simple: "itemReviewed": { "@type": "Restaurant", "name": "Example Bistro", "address": "42 …
Continue reading →
As regular readers will know, I love adding Semantic things to my blog. The standard WordPress comments HTML isn't very semantic - so I thought I'd change that. Here's some code which you can add to your blog's theme - an an explanation of how it works. The aim is to end up with some HTML which looks like this (edited for brevity): <li itemscope itemtype="https://schema.org/Comment" itemid="#246827"> <article> <time…
Continue reading →
Inspired by John Hoare at the Dirty Feed blog - I've asked the British Library to assign my blog an International Standard Serial Number (ISSN). An ISSN is an 8-digit code used to identify newspapers, journals, magazines and periodicals of all kinds and on all media–print and electronic. Why? Shut up. OK. It turns out that lots of people cite my blog in academic papers - so I wanted to make it slightly easier for scholars of the future to use metadata to trace my vast influence on Human …
Continue reading →
Academic citations are hard. One of the joys of the Digital Object Identifier System (DOI) is that every academic paper gets a unique reference - like: 10.34053/artivate.8.2.2. As well as always leading you to a URl of the paper, a DOI also provides lots of metadata. Things like author, publisher, ORCID, year of publication etc. I've built a simple website that turns any DOI into a semantic HTML reference - get started at DOI2HT.ML. Here's what it looks like: Pop a DOI in the box and hit…
Continue reading →
This is a real "scratch my own itch" post. I want to add Schema.org semantic metadata to the book reviews I write on my blog. This will enable "rich snippets" in search engines. There are loads of WordPress plugins which do this. But where's the fun in that?! So here's how I quickly built it into my open source blog theme. Screen options First, let's add some screen options to the WordPress editor screen. This is what it will look like when done: This is how to add a custom metabox to…
Continue reading →
My friends, and former employers, at the Government Digital Service have written a spectacularly good blog post "Making GOV.UK more than a website". In it, they describe how adding Schema.org markup to their website has allowed search engines to extract semantic content and display it to a user. For example, the "Learn to drive" page has content which can appear directly in a search engine: Even better, if you ask Siri / Google / Alexa for something, it can give an answer from an…
Continue reading →
I write book reviews on my blog. I also want to syndicate them to Goodreads. Sadly, Goodreads doesn't natively read the Schema.org markup I so carefully craft. So here's the scrap of code I use to syndicate my reviews. Goodreads API Keys Get your Keys from https://www.goodreads.com/api/keys You will also need to get OAuth tokens For this documentation, I'll use the example keys - please substitute them with your own keys. from rauth.service import OAuth1Service, OAuth1Session # Get a…
Continue reading →