During the middle of the 20th Century, the UK's Royal Air Force took thousands of photographs of the country from above. Think of it like a primitive Google Earth.
Those photographs are "Crown Copyright". For photographs created before 1st June 1957, the copyright expires after 50 years.
Recently, the organisation "Historic England" started sharing high-resolution copies of these photos on a nifty interactive map.

But there were two problems.
Firstly, they claimed that the photographs were still under copyright. This (no doubt inadvertent) mistake was pointed out to them and was eventually corrected.


It seems that, without announcement,
@HistoricEngland
have dropped the claim that copyright-expired pre-June 1957 RAF images are still in copyright, from their Aerial Photo Explorer
pic.x.com/uceK7qzQxd


The second, and to my mind more troubling, problem is that the photos were "protected" using SmartFrame's Digital Restrictions Management.
SmartFrame has some useful features - it allows for high-resolution photos to be loaded "zoomed out" in lower resolution. The user can then zoom in on a portion which then gets loaded as higher resolution. That's it really. SmartFrame's main selling point is that it "brings robust image control". AKA, it uses DRM to prevent users from downloading images.
It also promises "Complete image protection". This is nonsense. If you transmit an image to a user, the user can copy that image.
Here's how easy it is to download the images which SmartFrame claims to protect.
Screenshots
The obvious flaw in SmartFrame is that users can take screenshots of the high-resolution image. Zoom in, screenshot, pan left, another screenshot, repeat.
Of course, stitching together all those images is a bit of a pain. But perfectly possible to automate if you wanted to.
Canvas Chunks
The way SmartFrame works is by loading small "chunks" of the image and then drawing then on a <canvas> element.
In your browser's network inspector, you'll see each 256x256 sub-image loading.
 The images are not encrypted, so they can be saved directly. Again, it is a manual and tedious process to scrape them all and then stitch them together.
The images are not encrypted, so they can be saved directly. Again, it is a manual and tedious process to scrape them all and then stitch them together.
Inspecting the network requests shows that they all use the same Accept Header of authorization/wndeym9ajvin,*/* - that appears to be common across multiple SmartFrame instances. Bad form of them to reuse that key!
Canvas Access
It's fairly easy to download anything drawn onto a <canvas> element by running:
JavaScript
var c = document.getElementsByClassName("stage") c[0].toDataURL()
However, SmartFrame have overloaded the .toDataURL() function - so it produces a warning when you try that. It's simple enough to disable their JS once the image has loaded.
Of course, the <canvas> is smaller than the full resolution image - so you may need to manually increase its size first.
It's also possible to simply right-click on the <canvas> in the inspector and copy the Base64 representation of the image:
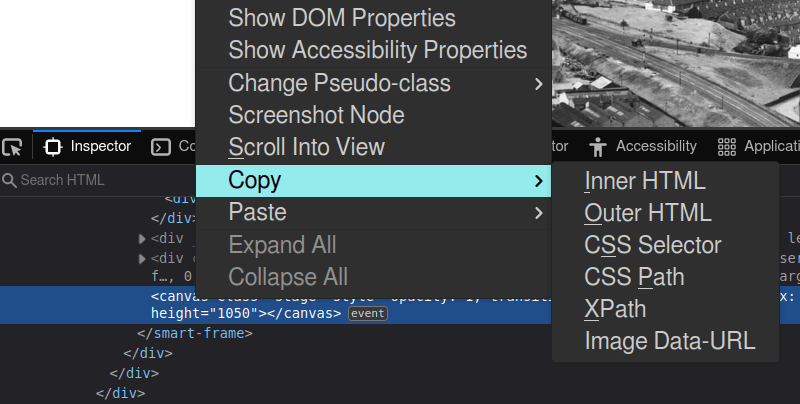
Putting it all together
I am indebted to Stuart Langridge for connecting all the dots. He has written and fully documented some code which is, essentially:
- Grab the canvas
- Resize it
- Wait several seconds for the image chunks to fully load onto the canvas
- Turn the canvas into a Data URL
- Download the data
It looks something like this:
var container = document.querySelector("div.articlePage.container"); container.style.width="6000px"; container.style.maxWidth="6000px"; setTimeout(()=>{ var stage = document.querySelector("canvas.stage"); var url = document.createElement("canvas").toDataURL.call(stage); var a = document.createElement("a"); a.href = url; a.download = "liberated.png"; a.click(); }, 3000);
And that's it. A user can paste a dozen lines of Javascript into their browser's console and get a full-resolution PNG.
Warnings
This technique should only be used to download images which are free of copyright restrictions.
Companies should be careful before buying a DRM solution and ensure that it is fit for purpose. SmartFrame really isn't suitable as sold. Despite its grandiose claims of "Super-strong encryption" and "Multi-layered theft-prevention" - it took less than weekend to bypass.
It is possible that SmartFrame will update their systems to defeat this particular flaw. But, thankfully, DRM can never work effectively. You can't give users a locked box and a key - then expect them to only unlock the box under the "right" circumstances. As Bruce Schneier once said:
trying to make digital files uncopyable is like trying to make water not wet.
40 thoughts on “Liberating out-of-copyright photos from SmartFrame's DRM”
This is a great workaround. It’s a tricky one because the work and cost of digitising and hosting/preserving the original photos plus hosting and maintaining the scans is not zero, but that in no way is reflected in the price they were trying to charge.
| Reply to original comment on twitter.com
Thank you for your input on this work, and for this write-up; and to Stuart Langridge and others in the linked discussions for their insights.
A few additional points:
There are apparently just over 38K such images (taken by the RAF before 1st June 1957, so out of copyright) on Historic England's "Aerial Photo Explorer" site
Historic England have refused to supply me with high-resolution copies of these images in response to my FoI request - https://www.whatdotheyknow.com/request/raf_images_on_aerial_photograph - because they are "reasonably accessible" to me; in other words, by me buying them at a cost of £12 plus VAT - EACH. Over half a million quid for all of them! How denying the public easy access to and free reuse of these out-of-copyright images meets Historic England's purpose to "[help] people care for, enjoy and celebrate England's spectacular historic environment" is not clear. Other organisations also use SmartFrame to prevent members of the public from downloading images of out-of-copyright artworks. Tate ("Our mission is to increase the public’s enjoyment and understanding of British art...", for example While copyright in more recent works should of course be respected, there are legitimate exceptions - https://www.gov.uk/guidance/exceptions-to-copyright - to UK copyright law (such as study, review or parody, etc), where copyright images may legally be downloaded and used (usual "I am not a lawyer" caveat applies). Downloading images whose copyright has expired is not "theft"
I do enjoy a bit of hacking in the browser's inspector, esp. when it's undoing someone else's copyright land grab.
shkspr.mobi/blog/2022/05/l…
#tw #linkblog
| Reply to original comment on twitter.com
Had a play with the JS and wrapped it in a TamperMonkey script https://pastebin.com/qYEy5C6L
Extra code includes checking for the original image width and setting the container width/maxwidth to that value, and also using the image name for the download.
The only thing missing for me was finding a way to download the images as jpegs instead of pngs. Whilst toDataURL can be passed the format type and compression eg toDataURL('image/jpg',1), once .call is introduced you can't use it.
Just realised you can get larger images, the container (at least on Chrome) has some negative margins when playing around with the size, so the result is smaller.
However if you just adjust the width of the smart-frame that works fine.
var sf = document.querySelector("smart-frame"); var wedge = document.querySelector("canvas.canvas-wedge"); sf.style.width = wedge.width + "px";First time I've used @simonw's datasette project, deployed to Glitch as he documents well aerial-photos-exploration.glitch.me/data Extracted metadata relating to this series of tweets and the images referenced -
| Reply to original comment on twitter.com
A new userscript has surfaced
http://ix.io/4BWp
It works on pages with a element, like the Historic England photos. Tested on firefox with violentmonkey, on HE.
Daniel
Tested on another site, works great dude. Thanks for sharing!
k.
ok i know this may sound a bit strange to you, but can someone make a how to do video of it? i'm pretty sure there may be people who are interested with downloading from smartframe without having knowledge/interest on coding issues (e.g. me).
I made a video just for you, k.
https://www.youtube.com/watch?v=NtZ1HaR3rJ4
k.
Dear Ben,
Thank you for your video. I had already figured out it btw thru your comment (it turns out it's easy in fact, and I just had to know using it on what). But I hope it will make it easy for the other people who also will look for it, and I hope they will also thank you for your help like I do.
I still use the code you gave btw (so far its only issue is .png format), and I can't explain how much of helpful to me. It really helped me a lot.
k.
Hungarian National Museum uses a website, called Museumap. Europeana is its partner. In the back they had a system that one could download a picture in HQ, but they changed it (idk when did they), former links doesn't work (for example those image thumbnails on omnia and europeana), and because not everything is on Europeana and Omnia, only way to do a proper search is its website.
One can only download a really small resolution one ("&size=masterview"), but it's obvious that original one is bigger than it.
Is there is a way to download like we do with smartframe?
@edent
Do you have a URL for a particular image? Maybe someone here can help.
k.
hi edent, sorry for not replying earlier, i totally forgot about it.
I think I was overstating the earlier form, because after giving a thought to it, I kind of remembered that HNM was never such in the first place. A larger resolution, maybe a bit, but I think it was always LR. Or maybe my disappointment lead me to think like that. I can't exactly tell, tbf.
Ray
Great to see there are other people who don't think the high-res versions should be locked away.
I couldn't get the script to work though as I think they may have updated how they have the html canvas set up slightly. I don't know too much about Javascript but after some digging I found that the canvas tags are now placed in a closed shadow-root node and seem to be inaccessible, so the query selectors now return null.
Hope someone can help as I would love to find a solution to this. Cheers.
Ray
So here's the method I ended up using:
Zoom into the image as far as possible and pan around to load all high resolution chunks (not entirely sure if this is one hundred percent necessary). Enlarge the canvas size by using the first three lines of the script:
var container = document.querySelector("div.articlePage.container"); container.style.width="6000px"; container.style.maxWidth="6000px";Right-clicked on the canvas element in the inspector and chose Copy> 'Image Data-URL' (as shown in the 'Canvas Access' section) to get the Base64 version. Pasted that into the address bar (in Firefox - presume it works similarly in other browsers) and pressed enter. Right-clicked the decoded Base64 image and saved the image as normal.
Not quite as automated as the original method, but I got the high-res images.
Concerned Citizen
Ray can you confirm if this still works? or do a step by step guide please, as I think the new "shadow-root" element is stopping this working
Ray's method works for me
Install the script as in the video and use the script as normal, so that the image blows up really big. Open dev tools (right click outside of the image ➡️ inspect) Find the canvas class="stage" and right click it ➡️ Copy ➡️ Image Data-URL Paste that image data into the address bar and there you have your image
Ray
Yes, I mention the shadow-root in my first comment. This solution was specifically to work around it, so yes, this method works. I may write up a guide at some point. If I do I will post the link here.
Ray
Here's a step-by-step guide: https://www.raymairlot.co.uk/blog/saving-images-from-historic-englands-smartframe-viewer
Concerned Citizen
Thanks Ray, turns out my problem was I was using chrome instead of Firefox - everything is identical apart from the very last step as chrome doesn't have the copy->image-data-url option.
Thank you so much for taking the time to write up a step by step guide.
Dave Hedhehog
This worked like a charm, thanks!
Any chance this latest method could be made to work in TamperMonkey?
Tampermonkey can't touch the shadow DOM so best you can do is use the script to blow up the image to the maximum proportions, then follow Ray's guide from step 4 onwards.
I have an edited version of the script that gets the correct image dimensions from the page. https://www.bfoliver.com/files/smartframe-userscript.js
But yeah it only gets you so far then manual intervention is required to actually do the download.
John
need help with the National Library of Scotland website, doesn't use SmartFrame but makes copying maps/images off of it rather complicated without having to manually stitch a whole bunch of canvas elements together.
@edent
Do you have an example link to an out of copyright image there?
John
The have numerous old OS maps and some OS maps that used those 1940s RAF photos, however some of the negatives they used are not currently available via Historic England or they have been lost/damaged since.
random selection of examples:
https://maps.nls.uk/view/103313042 (1850s) https://maps.nls.uk/view/101920008 (1897) https://maps.nls.uk/view/238419658 (1947)
Ray
Some initial investigation: For those interested the API for requesting image tiles is listed here: https://iiif.io/api/image/3.0/#4-image-requests
The original request URL for image 103313042 is https://map-view.nls.uk/iiif/2/10331%2F103313042/12288,6144,2048,2048/512,/0/default.jpg. The four comma separated values are x, y, width, height values for the tile region and the '512' is the tile size.
You can get the 'full' image by replacing the four region values with 'full': https://map-view.nls.uk/iiif/2/10331%2F103313042/full/617,/0/default.jpg however it is limited by a maximum size of 617 for some reason.
If you can get the image dimensions, this seems much more automatable.
John
oops... made a new message (below) rather than a reply to this.
k.
Hi John, try these iiff parameters, it gives the maximum resolution:
... /full/full/0/default.jpg
I use this method regularly since even though it's uploaded, some catalogues (like bla bla album from the bla bla university) won't permit you download it.
John
Looking at the main page you can seem to get the properties in json form on each image.
https://map-view.nls.uk/iiif/2/10331%2F103313042/info.json
Seems to the maximum area allowed per tile is 270,000 which is why you got the weird 617 number.
It also shows the width/height of each image.
So using your information and that the very top left corner of that image is this:
https://map-view.nls.uk/iiif/2/10331%2F103313042/0,0,520,519/full/0/default.jpg
but I assume its probably easier to render it all line by line rather than scan across and then go down..
https://map-view.nls.uk/iiif/2/10331%2F103313042/0,0,16432,16/full/0/default.jpg
That is the top 16 px of the entire image (~263k pixels), which makes it a bit easier to merge as it's just one direction. But of course each image is different in size. One of those other images is much smaller scan and you can get about 36px per line
Ray
I can't dedicate much more time to this, but this works on the few images I tried it on: https://gist.github.com/RayMairlot/1cc53363ce7946fc3c072a8d84d9ddad
I did not use (or recommend using) a line-by-line approach. This would result in requesting thousands of image chunks, which would either arouse suspicion, or get you blocked from making requests in some way. Instead, I used got as few chunks as possible using the maximum chunk size of 512 x 512.
k.
So, again smartframe huh! They and Getty Images are really trying their best. Is there any script that works on violentmonkey etc.? Doing it manually is kind of confusing for me (even doing the violentmonkey one was hard in the first place, my comments stays up there).
HedHuntr
G’day all. I’m currently in the process of trying to liberate some photos myself and have tried every method on here I can find, I just need a hand in trying to force the image to its full resolution lol
I had a surefire method up until today using Ben’s script, but unfortunately the script itself seems to not be working properly now, it won’t force the images to full res anymore.
Any help would be hugely appreciated.
@edent
It might help if you mention which website you're having problems with.
HedHuntr
Motorsportimages.com
My bad lol
KT
Haha glad found your post i was after one off motosportimages too from 1930 https://www.motorsportimages.com/photo/1017452406-24-hours-of-le-mans/1017452406
looks like they have blocked the enlarge function, have played with the inspect element and largest i can get is 1600px
HedHuntr
Yeah it’s a pain, I’ve found some photos that I’ve been after for about 8 years and am a little desperate to get the rest of them, I’ve got half and was none too pleased when I discovered they’ve broken the script.
Really hoping we can find a workaround.
XD
https://github.com/hoixw/SmartFrameDownloader/ allows me to download any smart-frame files. Just a simple tampermonkey script.
k.
Hi XD,
It's not working anymore, or I wasn't able to use it. Can you check it?