
A few years ago, I idly wondered "Whatever happened to URI Schemes?". Older communications protocols didn't rely on http. You can use mailto:me@example.com to send email, sms:+447700900123 to send a text message, and skype:terence.eden to use Skype. There are dozens of these sorts of protocols. But modern apps seem to prefer making everything an https: link. That way, if the user doesn't have…
Continue reading →

There's a new pre-print paper called Pinpointing the problem: Providing page numbers for citations as a crucial part of open science by Leon Y. Xiao and Nick Ballou. It's a short, easily understandable paper, and well worth a read. I think I disagree with nearly all of its conclusions! The main point, I agree with. Citing a whole paper is a lossy process. Saying "Smith, J (1963) Practical Time…
Continue reading →

The Guardian launched its online adventures back in 1999. At some point, they started using the name "Guardian Unlimited". Hey, the dot com boom made us all do crazy things! As part of that branding, they proudly used the domain GU.com Over time, the branding faded and GU.com became a URL shortening service. Tiny URls like gu.com/abc could be printed in papers, sent via SMS, or posted on…
Continue reading →

More on my experiments with silly Punycode domain names. http://↑↑↓↓←→←→ba.tk/ Yup, copy and paste that into your browser and it will resolve. (more…) …
Continue reading →
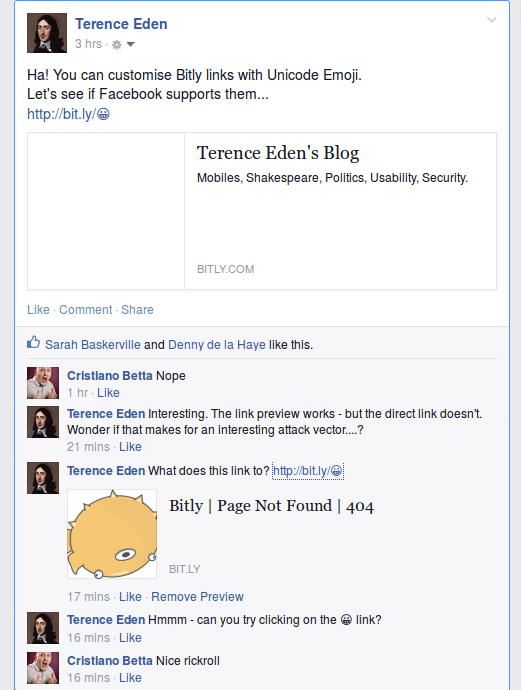
2025 Update - Bitly removed the ability to create emoji links, so some of these links are now dead. Facebook rewrite URLs with Unicode in the path - this is not best practice and could be dangerous. It is possible to create a URL like http://bit.ly/😀 - the Unicode characters are valid in the path. The URL Encoded representation is : bit.ly/%F0%9F%98%80 Facebook mangles these URLs in such a wa…
Continue reading →

I'm not a big fan of URL shortners - bit.ly, t.co, goo.gl, ow.ly, etc - I understand the need for them, but they seem to offer a fairly poor service in terms of privacy and usefulness. Take this recent example from Vodafone. Aside from the obvious downsides (user doesn't know where the link will take them, if it's compatible, link looks like gobbledegook, etc) there is a rather more…
Continue reading →

I hate shortened URLs with a passion. It makes it hard to see what a link is and whether I've visited it before. If they fail - like tr.im threatened to do - you lose your links with no way to see where they once went. So, hurrah for LongURLPlease - a service which takes those horrid little links and turns them in to full sized URLs. Here's the basic code in PHP to use the service. function l…
Continue reading →