
I've written before about the nascent WebMonetization Standard. It is a proposal which allows websites to ask users for passive payments when they visit. A visitor to this site could, if this standard is widely adopted, opt to send me cash for my very fine blog posts. All I need to do is add something like this into my site's source code: <link rel="monetization"…
Continue reading →

I've responsibly disclosed a small security issue with Mastodon (GHSA-8982-p7pm-7mqw). It allows a sufficiently determined attacker to use any Mastodon instance to redirect unwary users to a malicious site. What do you think happens if you visit: https://mastodon.social/@PasswordReset/111285045683598517/admin? If you aren't logged in to that instance, it will redirect you to a 3rd party site.…
Continue reading →

Suppose you are sent a link to a website - e.g. https://example.com/page/1234 But, before you can access it, you need to log in. So the website redirects you to: https://example.com/login?on_success=/page/1234 If you get the password right, you go to the original page you requested. Nice! But what happens if someone manipulates that query string? Suppose an adversary sends you a link like…
Continue reading →

A few weeks ago, I received a billing email from my phone provider O2. While glancing at it, I noticed all the images were broken. Viewing the source of the email showed that they were all coming from http:// mcsaatchi-email-preview.s3.amazonaws.com/o2/... What happens if we visit that domain? Ah, the dreaded "The specified bucket does not exist" error. At some point the images were…
Continue reading →

Codeberg is a hip new code hosting site - similar to GitHub and GitLab. And, much like Gits Hub & Lab, users can serve static content through Codeberg pages. Somehow I screwed up my configuration, and when I visited edent.codeberg.page/abc123 I got this error: Now, whenever I see something from the request echoed into the page's source, my hacker-sense starts tingling. What happens if I…
Continue reading →

A bit of a thought experiment - similar to my Minimum Viable XSS and SVG injection investigations. I recently found a popular website which echoed back user input. It correctly sanitised < to < to prevent any HTML injection. Except… It let through <h2> elements unaltered! Why? I suspect because the output was: <h2>Your search for ... returned no results</h2> And, somehow, the parser was g…
Continue reading →
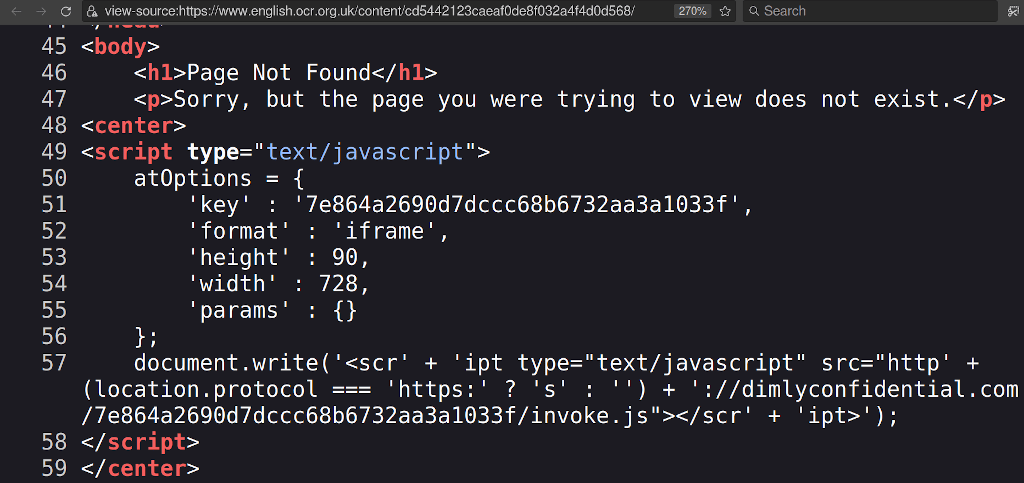
I hate academic tests. Wouldn't it be great if you could find the official answer papers? Oh, cool, the OCR Exam Board is hosting answer sheets for all my classes! What happens if I click it? Yeach! It redirects users to a scammy ebook service hosted on an external website. Which, I assume, the exam board does not endorse. Alongside exam books, textbooks, literary classics - there's a…
Continue reading →

Chrome for Android had a flaw which let one tab draw over another - even if the tabs were on completely different domains. A determined attacker might have been able to abuse this to convince a user to download and installed a spoofed app. See Chrome Bug #1242315 for details. Demo Here's a video of me on one site (Twistory.ml) opening a link to Twitter in a new tab. Twitter's mobile site…
Continue reading →
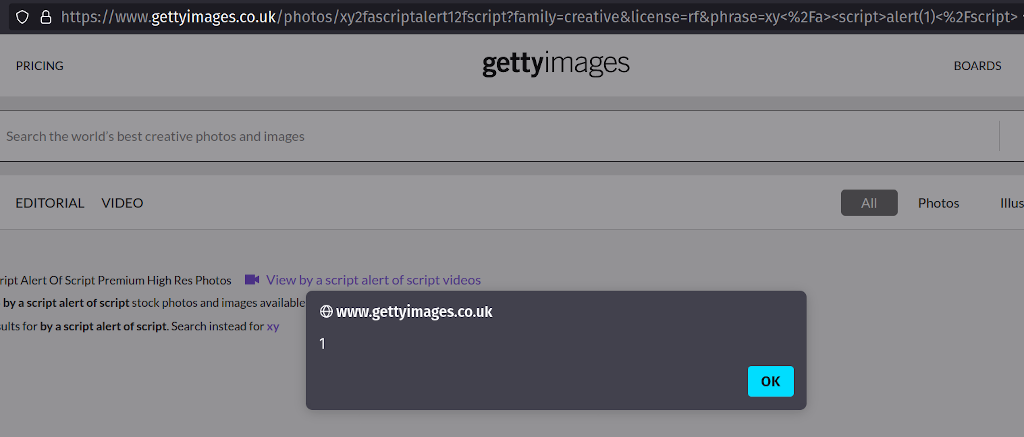
I've spent two months trying to report this issue to Getty images. They haven't responded to my emails, phone calls, Tweets, or LinkedIn messages. I've tried escalating through OpenBugBounty and HackerOne - but still no response. I've taken the decision to fully disclose this XSS because the Getty Images sites accept payments from users - and users need to be aware that the content they see on…
Continue reading →

Legacy websites are a constant source of vulnerabilities. In a fit of excitement, a team commissions a service and then never bothers updating it. Quite often the original owners leave the business and there's no-one left who remembers that the service exists. So it sits there, vulnerable, for years. The [REDACTED] website had a subdomain which was running KANA's IQ software which was last…
Continue reading →
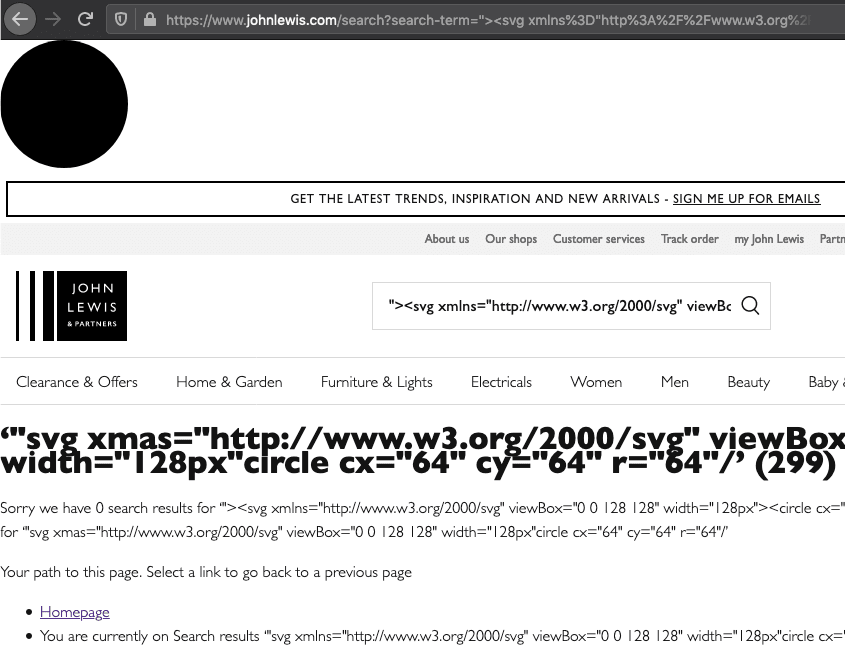
The HTML5 specification is complicated. I've been an author on it, and even I couldn't tell you all the weird little gotchas it contains. Between that and "idiosyncratic" browser engines, it's a wonder the world wide web works at all. Let's talk about the humble <meta> element. As its name suggests, it contains metadata about the document. A typical element might look like this: <meta…
Continue reading →

tl;dr Google forgot to renew a domain used in their documentation. It was mildly embarrassing for them. And possibly a minor security concern for some new G-Suite domain administrators Background Choosing a good example domain, to use in documentation, is hard. You want something which is obviously an example, so that users understand they have to substitute it for their own details. But…
Continue reading →