I read this brilliant blog post by Wouter Groeneveld looking at how many dead links there were on his blog. I thought I'd try something similar.
What is a broken link?
Every day, I look at the On This Day page of my blog and look at that day's historic posts. I click on every link to see if it is still working. If it isn't, I have a few options.
- If the site is working, but the content has moved, I change the link to point at the content.
- If the site is dead, or the content isn't there, I stick the URl into the WayBack Machine and pick the archive closest to the publication date.
- If the archive doesn't have it, I try to find a link from around the same date and point it to that.
- If not, I remove the link.
Why don't I just cURL the URl and see if it responds with a 2xx HTTP code?
I used to use an automated checker to test my links. But spam sites lie. Lots of the dead sites have been taken over by scammers, spammers, and AI grifters. They return an HTTP OK and then serve up advertising. Yeuch! So now I spend each morning Tending To My Digital Garden and manually checking the links.
So, let's scan through every link within my blog posts and see which ones have been archived.
Results
Here's a stacked chart showing blog posts from 2008 until today:

And, if you prefer percentages, here's another chart:
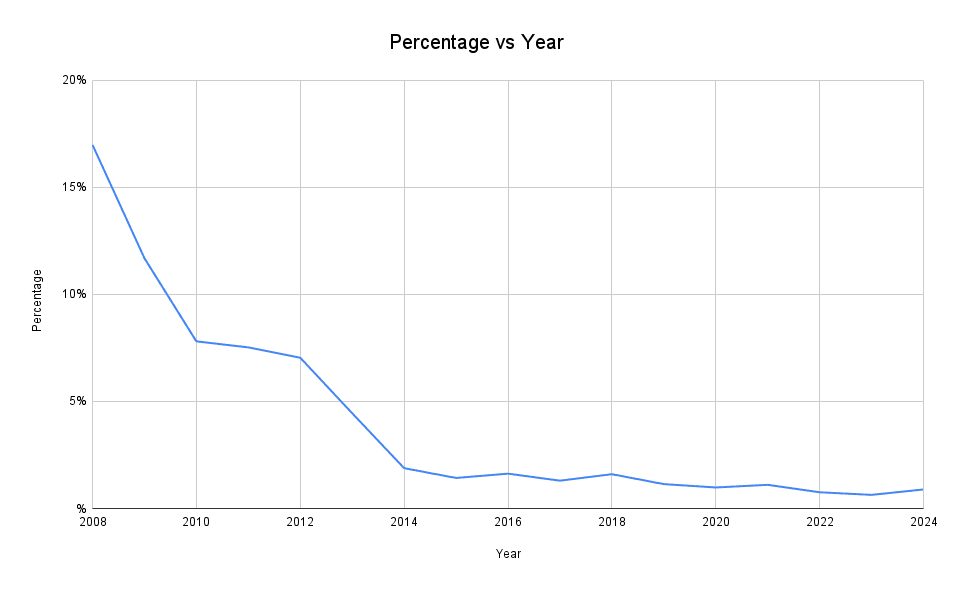
Rather unsurprisingly, the older posts have the most link-rot.
Here's the data if you want to play with it yourself:
CSV
Year,Total,Archives 2008,159,27 2009,1335,156 2010,1166,91 2011,1130,85 2012,1392,98 2013,1889,84 2014,1858,35 2015,3016,43 2016,2274,37 2017,1309,17 2018,1561,25 2019,1580,18 2020,3362,33 2021,3621,40 2022,2904,22 2023,2358,15 2024,2136,19
Deficiencies
There will be some links that I haven't spotted. There will be dead links in review metadata and in comments. My code might not have accounted for some weird edge cases in the HTML.
But, generally, it should be a roughly accurate assessment.
Generating the data
Using the WP CLI, this can be run with wp eval-file archive.php:
PHP
<?php // Load the WordPress environment require_once( "wp-load.php" ); // Loop through the desired years for ( $year = 2008; $year <= 2024; $year++ ) { // Initialise the counters $total_links = 0; $archive_links = 0; // Get all the published posts for that year $posts = get_posts( [ "date_query" => [ [ "year" => $year, ], ], "post_type" => "post", "post_status" => "publish", "numberposts" => -1, ] ); // Loop through each post foreach ( $posts as $post ) { $ID = $post->ID; // Render the content of the post $content = apply_filters( "the_content", get_the_content( null, false, $ID ) ); // Count total occurrences of "<a href=" preg_match_all( '/<a href=/i', $content, $matches ); $total_links += count( $matches[0] ); // Count total occurrences of "<a href=" which contain "archive.org" preg_match_all( '/<a href=["\'][^"\']*archive.org/i', $content, $archive_matches ); $archive_links += count( $archive_matches[0] ); } // Display the results as CSV echo "{$year},"; echo "{$total_links},"; echo "{$archive_links}\n"; }
8 thoughts on “How bad is link-rot on my blog?”
@Edent I did a similar exercise a couple years ago: Link survival
I haven't tended to my digital garden by fixing any of those links yet. Your post is inspiring me to do so. I have two questions, if you don't mind: what is your reasoning for removing the link entirely if you can't find a good replacement? Do you leave any sort of hint that it once was a link?
| Reply to original comment on fedi.esgeroth.org
@prijks for some things, I can see that a broken link might have semantic value. E.g. example.com/recipies/soufle.html
But most of the time a broken link is just a frustrating user experience. I'll sometimes put a <del> through it, or leave an <ins> with a note.
Of course, I'm not your boss. Do what's right for your site 😄
| Reply to original comment on mastodon.social
I care about link rot on my blog as well, but rather than fixing every post I just fix the ones that still get enough views. "Enough" depends on how I feel on any given day, I admit. If an old post suddenly gets a surge of views, I'll review the links on it and fix or remove the broken ones. I never thought about linking to the Wayback Machine; thanks for that tip.
I would love to be able to, when adding links, to be able to add specific keywords to it. Then have a spider (like Xenu's Link Sleuth or the old ODP's Robozilla) occasionally scan all links on my site and if a linked page doesn't have those keywords on it, it will then check archive.org around that date for a matching page and auto-link it or alert me that the link is stale.
@Edent on my blog? no broken links at all! how implausible!
this is, of course, because I'm using @rem's rather cool https://unrot.link/ 🙂
unrot•link
| Reply to original comment on mastodon.social
Chris Coyier
Nice. Came here to mention that service.
Mario Mario
This service does exactly the thing Terence already mentioned above (proceeds if 200 and redirects if 404), so it obviously doesn't detect spam sites or otherwise massively changed content.
https://remysharp.com/2023/09/26/no-more-404#backend--server-side
Link seals provide a quick soft-check utility for link health on your web spaces.
| Reply to original comment on mistystep.org
More comments on Mastodon.