Microsoft loves you and wants to protect you. So every time you receive an email with a link in it, Microsoft Outlook helpfully rewrites it so that it goes through their "safelinks" system.
Safelinks allow your administrator, or someone at Microsoft, to stop you visiting a link which is malicious or suspicious. Rather than going to example.com, your link now goes to safelinks.protection.outlook.com/?url=example.com.
Hurrah! If you accidentally click on a naughty link you won't cause chaos and ructions.
Except, there's a tiny problem. People like to copy and paste links that they receive. Someone sends an email which says "here's the link to that report you asked for" which then gets copied into a document or a web page.
For example, I was reading this official document from the UK's Department of Health and Social Care. Slap bang in the middle is a link to another report:

That forces everyone who visits that link to go through Microsoft's proxy. That might protect users if a link later becomes suspicious. But, more likely, it will be used in analytics to further profile users who click on links. It also undermines a user's ability to see the final destination of a link unless they can manually URl-decode content in their head.
It appears that every large organisation which uses Microsoft is prone to this failure. Lots of UK Government departments publish content with safelinks:
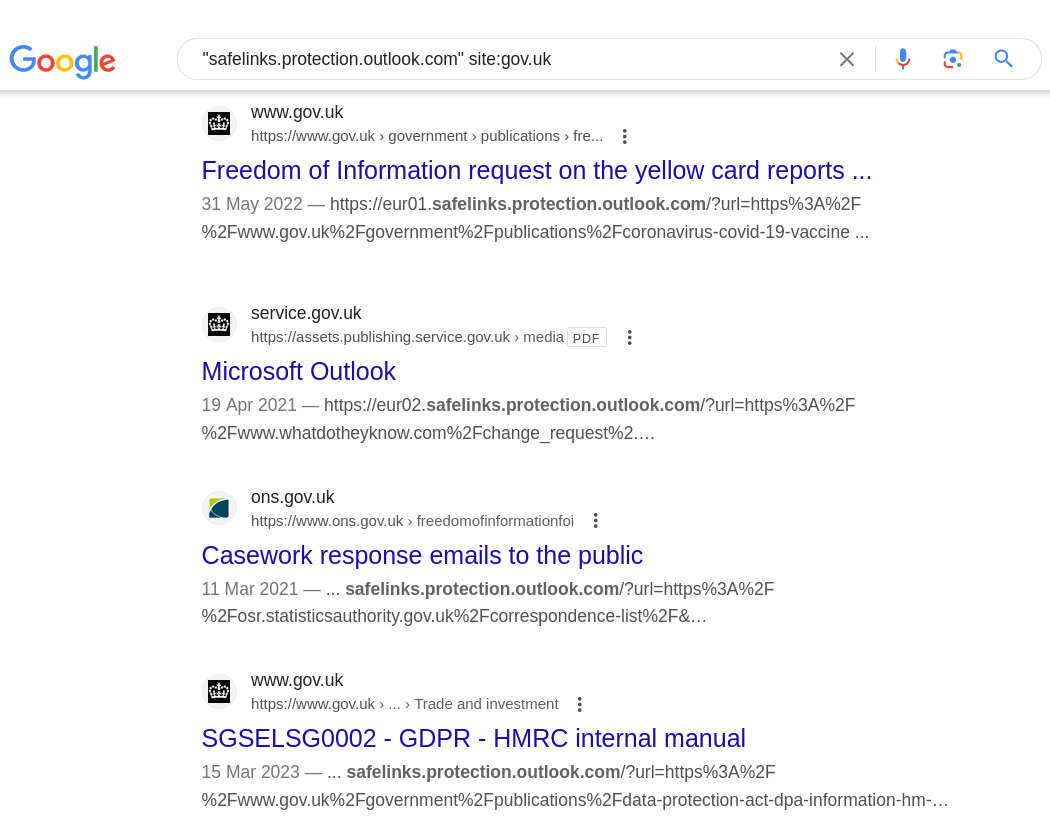
The US Military too:

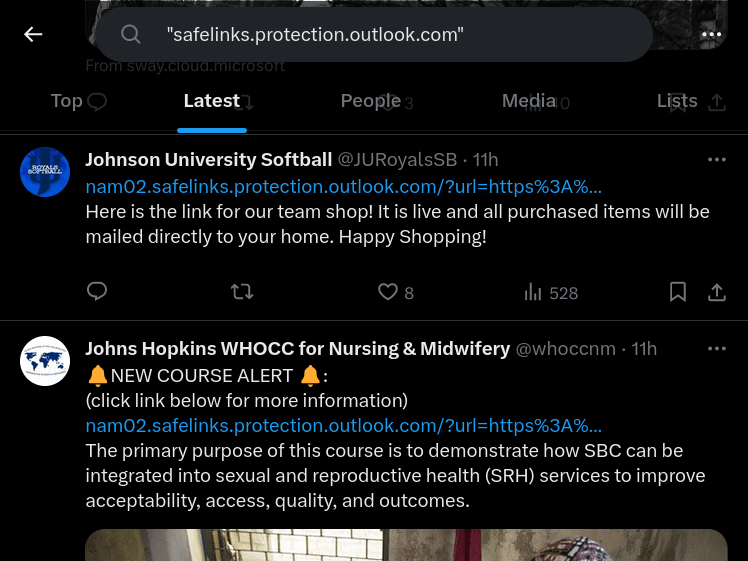
It's all over Twitter:
And there are hundreds of academic works infested:
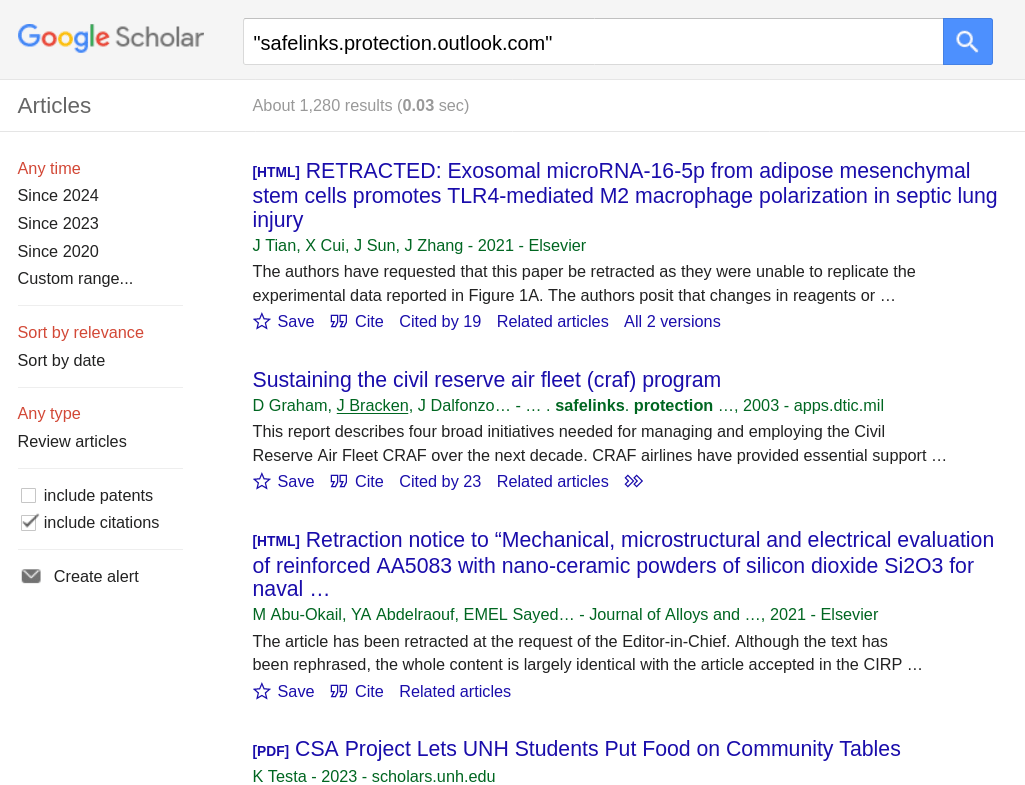
Look, I get why people do this. They copy a link from an email, paste it in, click it, and it works. No one writes raw HTML by hand, nor should they have to. Our WYSIWYG tools work really well and hide all the mumbo-jumbo. Copy editors look at text; not hypertext. It's only nerds like me who hover over a link before clicking on it.
Perhaps I should stop worrying? Perhaps it is OK that Microsoft intercepts the clicks from people all around the world? Perhaps they can competently run a proxy which detects and blocks inappropriate content? Perhaps they won't ever abuse that facility?
Here's my prediction. In the next five or so years, Microsoft is going to accidentally shut off *.safelinks.protection.outlook.com and a million copy-and-pasted links across the web are going to break.
Think I'm over-reacting? A decade ago, Microsoft got rid of their MS Tag product and, shortly after, all their proxy links were shut off. Similarly, other proxies like McAfee have shut down with little warning.
Or maybe Microsoft's sub-domains will be hijacked?
Either way, if you work in digital publishing, please make sure that your links point directly to the content that you want; not to Microsoft's safelinks service.
16 thoughts on “Safelinks are a fragile foundation for publishing”
Reading Time: < 1 minute A little app that takes the mangled URLs generated by Microsoft 365’s Safelinks link checking service and decodes them to recover the original target. Just pop the Safelinks redirect URL in this widget and press enter or click the button. Then copy the retrieved URL and use it wherever you need it. Before you use …
Continue reading “Safelinks original URL decoder”
| Reply to original comment on design.scotentblog.co.uk
@Edent Link rot is a far more serious issue than privacy in this case. But on privacy I have a couple of thoughts:
* If Microsoft were to be profiling people across the web that click on such links they'd be in violation of the GDPR as clicking a link is not informed consent.
* If you publish such a link and Microsoft track you, would you as the publisher be in violation of the GDPR for not showing a tracker banner seeking consent for sharing data with Microsoft? Maybe.
| Reply to original comment on social.vivaldi.net
Can be even worse. Can be a redirection service that requires the corporate SSO.
Or multiple layers of redirection due to multiple layers of corporate "security" tools.
And I'm not making this up.
I wrote a widget that reverse-engineers Safelinks redirects and gives you the original URL.
https://design.scotentblog.co.uk/toolbox/safelinks-original-url-decoder/
@EdentSafelinks URL decoder
| Reply to original comment on mastodon.scot
@Edent …and it’s SO slow I think it’s broken every time I use it, and often click more than once…
| Reply to original comment on ohai.social
@Edent Everything in GDocs is like this too.
| Reply to original comment on mastodon.social
@Edent I blame M$ themselves, when someone copies a URL from outlook it should be the original URL, especially as it often is, even a mouse hover will show the original URL!
| Reply to original comment on mastodon.radio
@Edent part of what I do when copyediting science stuff is check URLs in the prose for just this crap (we try and have them in full so it can be seen in a printed PDF - although there are exceptions). In fact, we try and click through every link too. I’ve had an author make a typo and it go somewhere dodgy. Mind every doi link is relying on crossref to do its thing redirecting to right place, but I know also one of my colleagues does act on error reports we get from them!
| Reply to original comment on mastodon.me.uk
Ivan
I've also seen links from Google search results (
https://google.com/url?lots_of_noise), but those are harder to search for. Also, Google is not entirely consistent about giving you tracking links in the search results.@Edent i love it wheni try to visit the link to something on the university oit page that was sent to me by the university oit office and can't without excavating it from the safelink cruft because oit has decided to switch us to outlook "infrastructure"
| Reply to original comment on post.lurk.org
@blog They can leak email addresses too…
https://vk4msl.com/2022/08/11/html-email-ought-to-be-considered-harmful-auda-shows-us-why/
| Reply to original comment on mastodon.longlandclan.id.au
@blog this really surprises me tho. Do people really copy and paste links without even looking at the actual website it goes to? Like, to post something on twitter, sure, why not. But before putting something in an official document, or a scientific paper, you would expect people to check their link to see if it is not a redirect, and to remove any tracking data.
| Reply to original comment on mathstodon.xyz
@blog @paurea Yes to all of this, and also: my previous corporate job used this, and in an engineering org that has to mail around API endpoints it’s extra infuriating. I don’t know how much cumulative time I lost to tracking down whether there was an actual technical problem or someone was just using a “safelink” when they shouldn’t.
| Reply to original comment on pdx.social
@blog safelinks are also a pain for those of us who links to download data and want or need to wget / curl which is not possible without recoding.
And I am not going to download several 5G+ data files via the browser.
#bioinformatics #datascience
| Reply to original comment on genomic.social
I'll say it... I hate safelinks. Obfuscating links in the interest of "safety" irks me. It also makes me think the person who shares it hasn't read the thing it links to properly
| Reply to original comment on bsky.app
I've seen this increase. We try to catch them in Editorial / 2i sometimes they slip through. We've setup a policy on an automated scan to catch the rest
| Reply to original comment on bsky.app
More comments on Mastodon.