The future of the web, isn't the web
My friends, and former employers, at the Government Digital Service have written a spectacularly good blog post "Making GOV.UK more than a website".
In it, they describe how adding Schema.org markup to their website has allowed search engines to extract semantic content and display it to a user. For example, the "Learn to drive" page has content which can appear directly in a search engine:
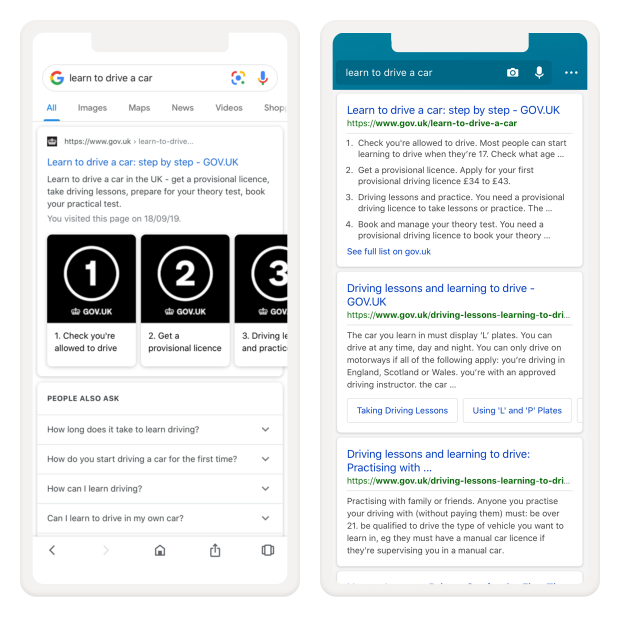
Even better, if you ask Siri / Google / Alexa for something, it can give an answer from an authoritative source:

This is the death of the web. Long live the web!
Why this is really important
Your information has to be where your users want to access it. Not where you want to display it. I remember sitting in a housing benefits office, watching someone playing on their PlayStation Portable - or so I thought. On closer inspection, she was browsing the GOV.UK web pages to see what the process was for claiming benefits. Web browsers are everywhere!
But the future is not a browser. It is a User-Agent. It could be your search engine, smart watch, voice assistant, or something yet to be invented.
History
The web is great. But its real power was in separating content from design.
- HTML for your words.
- CSS for your layout.
That's a good start. But we can go one deeper. Because content isn't HTML.
Your content probably lives in a database. Whether you're running a personal blog, or an ecommerce platform, the content is actually data. You render it as HTML because that's what's easiest for humans to read on a screen.
But... not everyone is able to read a screen. Nor do they always want to.
Do we need to write custom CSS just in case our data is rendered on a smartwatch? Or a TV? Or an Internet Connected Fridge? No! The User-Agent should be able to grab the data and render it appropriately.
At the moment, we're mostly stuck in this paradigm:
Data ➡ HTML ➡ CSS ➡ Browser ➡ 👀
But because our content is just data in a database, we're not restricted to that. It can just as easily be:
Data ➡ Speech Synthesis Markup Language ➡ Alexa ➡ 👂
Too many APIs
And that is what I love about HTML + microdata / Schema. No one is going to use your API - unless you are a megacorp. But if the data is already in your web pages, they don't have to do anything fancy.
No one is ever going to use my blog's API. But your Kindle could come across my web page, and see this recent review - embedded in it is this data:
JSON
{
"@context": "http:\/\/schema.org",
"@type": "Review",
"author": {
"@type": "Person",
"name": "@edent",
},
"itemReviewed": {
"@type": "Book",
"name": "This Is How You Lose the Time War",
"isbn": "9781534431003",
"author": {
"@type": "Person",
"name": "Amal El-Mohtar",
"sameAs": "https:\/\/www.goodreads.com\/book\/author\/Amal+El-Mohtar"
},
},
"reviewRating": {
"@type": "Rating",
"worstRating": 1,
"bestRating": 5,
"ratingValue": 5
}
}
And - hey presto! - it can find the book via ISBN, show you books by the same author, and display the rating I gave the book. All without needing any fancy AI or Natural Language Processing.
Your smart-fridge can find a recipe and display the steps you need to take in order to prepare the perfect moussaka. You don't need to build an app for Samsung fridges, and another one for Smeg fridges. Just build a website and embed your data in the pages!
The future
So, I hope that the future is more data-in-the-web & more diverse User Agents.
You will have many, many User Agents - your car, your speaker, your microwave - all of them grabbing data on your behalf, rendering it, processing it, giving you information in the format which works best for you.
It will all be powered by the web, but won't be accessed by what you think of as a traditional web browser.
| Reply to original comment on twitter.com
| Reply to original comment on twitter.com
Also no API involved but it allows for some fancy stuff.
[Feel free to remove that manual comment now that you have webmentions] The future of the web, isn’t the web by @edent @edent
My friends, and former employers, at the Government Digital Service have written a spectacularly good blog post “Making GOV.UK more than a website”.
In it, they describe how adding Schema.org markup to their website has allowed search engines to extract semantic content and display it to a user. For…
| Reply to original comment on beko.famkos.net
Also no API involved but it allows for some fancy stuff.
The future of the web, isn't the web · Jamie Tanna | Software (Quality) Engineer said on :
| Reply to original comment on
This reminds me of Drew McLellan’s talk from 2006 Can Your Website be Your API? or Jeremy Keith’s slightly more recent talk The Spirit Of The Web from 2012 which I’d listened to recently.
I like the idea of experimenting into some of these new areas, but I’m worried about who owns some of these gateways and how they treat the data–both from the perspective of the site owners as well as from the users who are encouraged to access data through them. How do our power structures change based these new modalities? Is it responsible?
| Reply to original comment on boffosocko.com
| Reply to original comment on twitter.com
| Reply to original comment on twitter.com
Supplying JSON-LD as sidecar data (accessible through an API or whatever) is fine, but this mechanism for providing it inside a script blob is kind of annoying to deal with for both the producer and the consumer.