More adventures with Unicode. I logged in to my Virgin Media account to see when my promotional discount would end. Here's what their billing PDF said.

Let'S Ignore The Weird Capitalisation Virgin'S System Uses. What's that  doing there?
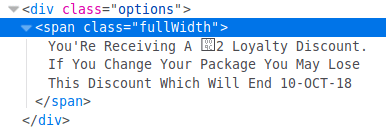
Their website says:
No  symbol, but also no £ sign. Ah, but let's look at the underlying code.
What's that weird character? It is the control character string terminator, of course...
Well, my discount is nearly finished, so I asked them for a larger discount. "Sure!" they said "How does Ÿ3 sound?"

Amusingly, when I copy the Ÿ from that PDF, it shows up as the character œ!
What's Going On?
I've written extensively about how the £ symbol is encoded - but here's a primer.
-
£in ISO-8859-1 (Latin-1) is decimal163. -
£in Unicode is also163- but it gets stored as two UTF-8 bytes -194&163. In hex this is0xC2 0xA3. - In
Windows-1252
- the legacy encoding for ancient version of Microsoft's software -
0xC2gets rendered asÂ.
So, at some point, Virgin's billing software is seeing 0xC2 0xA3, encoding it as £, and then grabbing the first character to print on the bills.
Where do the other characters come from?
- In
Code Page 437
- an ancient IBM encoding - the
£symbol is0x9C. -
0x9Cin Windows 1252 isœ - The String Terminator is
0xC2 0x9C
And the Ÿ character? Not a clue! Inspecting the raw text of the PDF shows the underlying code is:
6m \2343.00 RIV Discount.
PDFs escape octal characters. Octal 234 is decimal 156 - which is hex 0x9C.
Nearest I can get is the ISO/IEC 8859-15 encoding, where œ is 0xBD and Ÿ is 0xBE. Perhaps a font substitution error?
Everything is awful
This isn't just ugly. It points to the fact that Virgin don't test their software and don't upgrade their systems. What other horrors lie in their technology stack?
And it isn't just a tech issue. It is bad for screenreaders - meaning visually impaired users get a poor experience.
The year is 2018. And we're still battling text encoding issues due to crappy software.
3 thoughts on “Virgin Media don't understand Unicode”
Alex
I also have concerns with the way Virgin Media operate their account security. The highly restrictive password rules (7-10 chars, must start with a letter, etc) suggests it isn’t a very sophisticated implementation and I would guess not hashed before storage. I’ve raised this by email and twitter on a number of occasions but it has been ignored.
The lack of testing you’ve identified on their website reinforces my worries.
Tom
The year is 2021 and I still just received and email telling me “You’Re Receiving A œ3 Discount” and came and found this post. Good to know my fee’s are being used to keep this telecoms company on top of it’s tech.
Dr. Mantis Toboggan
2024 and just recieved the exact same thing! "You're receiving a œ3 discount." Nice!
What links here from around this blog?