únicode is hard
In the last couple of months, I've been seeing the ú symbol on British receipts. Why?

1963 - ASCII
In the beginning* was ASCII. A standard way for computers to exchange text. ASCII was originally designed with 7 bits - that means 128 possible symbols. That ought to be enough for everyone, right?
Wrong! ASCII is the American Code for Information Interchange. It contains a $ symbol, but nothing for other currencies. That's a problem because we don't all speak American.
*ASCII has its origins in the telegraph codes of the early 20th Century. They derive from Baudot codes from the 19th Century.
1981 - Extended ASCII
So ASCII gradually morphed into an 8 bit language - and that's where the problems began. Symbols 0-127 had already been standardised and accepted. What about symbols 128 - 255?
Because of the vast range of symbols needed for worldwide communication - and only 256 symbols available in an 8 bit language - computers began to rely on "code pages". The idea is simple, the start of a file contains a code to say what language the document is written in. The computer uses that to determine which set of symbols to use.
In 1981, IBM released their first Personal Computer. It used code page 437 for English.
Each human script / alphabet needed its own code page. For example Greek uses 737 and Cyrillic uses 855. This means that the same code can be rendered multiple different ways depending on which encoding is used.
Here's how symbols 162, 163, and 164 are rendered in various code pages.
| 162 | 163 | 164 | |
|---|---|---|---|
| Code Page 437 (Latin US) | ó | ú | ñ |
| Code Page 737 (Greek) | λ | μ | ν |
| Code Page 855 (Cyrillic) | б | Б | ц |
| Code Page 667 (Polish) | ó | Ó | ñ |
| Code Page 720 (Arabic) | ت | ث | ج |
| Code Page 863 (French) | ó | ú | ¨ |
As you can see, characters are displayed depending on which encoding you use. If the computer gets the encoding wrong, your text will become incomprehensible mix of various languages.
This made everyone who worked with computers very angry.
1983 - DEC
This is silly! You can't have the same code representing different symbols. That's too confusing. So, in 1983, DEC introduced yet another encoding standard - the Multinational Character Set.
On the DEC VT100, the British Keyboard Selection has the £ symbol in position 35 of extended ASCII (35 + 128 = 163). This becomes important later.
Of course, if you sent text from a DEC to an IBM, it would still get garbled unless you knew exactly what encoding was being used.
People got even angrier.
1987
Eventually, ISO published 8859-1 - commonly known as Latin-1.
It takes most of the previous standards and juggles them around a bit, to put them in a somewhat logical order. Here's a snippet of how it compares to code page 437.
| 162 | 163 | 164 | |
|---|---|---|---|
| Code Page 437 (Latin US) | ó | ú | ñ |
| ISO-8859-1 (Latin-1) | ¢ | £ | ¤ |
8859-1 defines the first 256 symbols and declares that there shall be no deviation from that. Microsoft then immediately deviates with their Windows 1252 encoding.
Everyone hates Microsoft.
1991 - Unicode!
In the early 1990s, Unicode was born out of the earlier Universal Coded Character Set. It attempts to create a standard way to encode all human text. In order to maintain backwards compatibility with existing documents, the first 256 characters of Unicode are identical to ISO 8859-1 (Latin 1).
A new era of peace and prosperity was ushered in. Everyone now uses Unicode. Nation shall speak peace unto Nation!
2017 - Why hasn't this been sorted out yet?
Here's what's happening. I think.
- The restaurateur uses their till and types up the price list.
- The till uses Unicode and the
£symbol is stored as number163. - The till connects to a printer.
- The till sends text to the printer as a series of 8 bit codes.
- The printer doesn't know which code page to use, so makes a best guess.
- The printer's manufacturer decided to fall back to the lowest common denominator - code page 437.
-
163is translated toú. - The customer gets confused and writes a blog post.
Over 30 years later and a modern receipt printer is still using IBM's code page 437! It just refuses to die!
Even today, on modern windows machines, typing alt+163 will default to 437 and print ú.
As I tap my modern Android phone on the contactless credit card reader, and as bits fly through the air like færies doing my bidding, the whole of our modern world is still underpinned by an ancient and decrepit standard which occasionally pokes its head out of the woodwork just to let us know it is still lurking.
It's turtles all the way down!
ASK Italian last week
PJ Evans
I went to see a film today. I thought @edent might appreciate what I saw when buying my ticket.
Skylar
Or is it?
Of course, when we look at the full receipt, we notice something weird.

The £ is printed just fine on some parts of the receipt!
⨈Һ?ʈ ╤ћᘓ ?ᵁʗꗪ❓
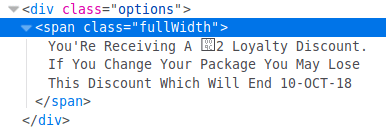 Virgin Media don't understand Unicode
Virgin Media don't understand Unicode
anonymfus says:
Cyrillic is not a language, it's an alphabet/script. Codepage 855 was used for Cyrillic mostly in IBM documentation. In Russia codepage 866 was adopted on DOS machines, because in codepage 855 characters were not ordered alphabetically.
It's only true for machines where so called "OEM codepage" is configured as codepage 437. But in Russia it's codepage 866 by default, so typing alt+163 prints г.
Terence Eden says:
Matthew says:
David Moles says:
Dario says:
Cheers!
Sam says:
Possibly, the POS system just doesn't handle the string properly when printing out. Don't forget that even if all the strings are being stored properly, the software still has to "compose a page" if it isn't sending "plaintext" to the receipt printer.
Suppose, for example, that you can supply the point of sale system with, say, a CSV file listing the menu items, their prices, their categorisation, and any other information required. If the encoding of this file were misinterpreted, these phantom ú characters would creep into the system's database at that point. So while the system is perfectly capable of telling the printer to print a pound sign (as we can see it manages on the right) the reason it doesn't do that for the offending items on the left is that the system's internal data store genuinely thinks that the name of that item is "ú5 COCKTAIL" because the name was read in wrong while the system was being set up.
name says:
This statement doesn't make sense. Unicode isn't an encoding, UTF8/UTF16/etc... are. So while £ has the codepoint of U+0163, the UTF8 encoding would be 0xC2 0xA3 and the UTF16 encoding is 0x00A3.
If the printer was expecting Windows codepage 436, it would have displayed the UTF8 as ┬ú (assuming the font supported it). If it was sent as UTF16, it probably would just skip the NUL byte and only show the ú.
All speculation unless you know what encoding is transmitted on the wire, and what encoding the printer expects.
G says:
Terence Eden says:
Douglas says:
Phlip says:
But the cocktail description isn't managed by the POS, it's managed by some sort of product database, which is stored as ISO-8859-1 (or, more likely, as Win1252), and then the POS is pulling those descriptions out of the DB and sending them along untranslated.
That's where the encoding error happens... the POS is treating the product DB as cp437, but the management software is treating it as cp1252. Likely, the two are made by different companies, so there's probably endless specs somewhere that would tell you who was right... and if you locked the two comapnies' lawyers in a room with a tarp and a straight razor you'd probably eventually get an answer as to who that is... but without that it's not particularly obvious who's to blame, other than "every programmer who allowed this encoding problem to continue".
fastboxster says: