I've found an interesting, but low severity, way for a malicious user to selectively deny access to specific GitHub issues and Pull Requests.
This doesn't affect the whole site - just targeted pages. It doesn't require elevated permissions, nor any special skills. This is just GitHub punching itself in the face.
Here's how it works.
- An attacker creates thousands of comments in their own repos which contain references to a specific issue or PR in an external repo.
- When that issue or PR page is loaded, GitHub tries to render every single reference from all repos.
- This often makes the page completely unavailable (Unicorn Error) and always slows down page loading and rendering time.
- Site owners are unable to remove the malicious links, leading to a either permanent degradation of page loading time, or a page which can never be loaded.
Uses
Suppose a GitHub issue is talking about a security vulnerability - a malicious actor can deny access to that page.
Similarly, a competitor can disrupt your normal GitHub workflow.
Users on slow / mobile Internet connections will have a markedly worse experience accessing pages.
Examples
A good source of examples is the Linux Kernel.
Take a look at Pull Request #12.
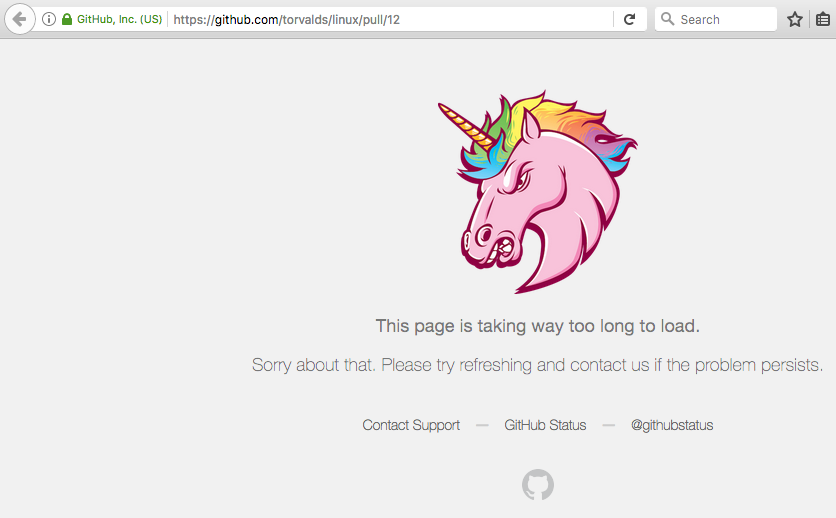
(Edit - this page now appears fixed and no longer times out.)
Most of the time, the page fails to load. When it does load, it renders slowly on desktop. At the bottom are hundreds of links to places which appear to refer back to this. But they don't! Instead, the comments often contain lists of numbers like:
#5 ffffffff812a12de (____fput+0x1e/0x30)
#6 ffffffff8111708d (task_work_run+0x10d/0x140)
#7 ffffffff810ea043 (do_exit+0x433/0x11f0)
#8 ffffffff810eaee4 (do_group_exit+0x84/0x130)
GitHub gets confused and thinks that those numbers refer to an Issue or Pull Request.
When it tries to render the page, it can timeout while gathering all of the comments which appear to be links.
In my experiments I found dozens of pages which repeatedly gave timeout errors.
Severity and Disclosure
This is a low impact bug.
When there are thousands of comments across dozens of repositories, gathering all references can be time consuming. Once the servers have managed to successfully render the page, it reduces the likelihood of the page being blocked again.
I reported it via HackerOne on the 13th of February. The next day GitHub responded:

In the meantime, there isn't much you can do to protect yourself. There's no way to bulk remove malicious references.
On GitHub's side, they should be truncating pages before a timeout occurs. They already do this on mobile - perhaps it should be standard everywhere?