If you've been following this blog, you'll know that Google unjustly shut down my YouTube channel. They've now reinstated it - but I can no longer trust them as custodians of my data.
So, here's a quick tutorial on how to download all your videos - and metadata - from YouTube.
The Official Way
Google offers a "takeout" service which will allow you to package up all your YouTube videos for export.
It creates a multi-gigabyte archive - which isn't particularly suitable for hosting elsewhere.
 Once the archive is created, you have to download it in 2GB chunks. The archives are only available for 7 days - so if you're on a normal speed Internet connection, you might not be able to grab everything.
Once the archive is created, you have to download it in 2GB chunks. The archives are only available for 7 days - so if you're on a normal speed Internet connection, you might not be able to grab everything.
If you do manage to download everything - you'll find another problem.
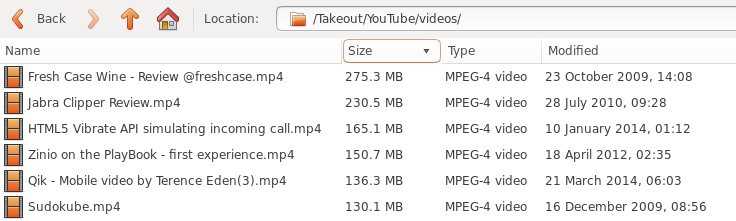 The files are enormous because you're downloading the originals - not the web-optimised versions.
The files are enormous because you're downloading the originals - not the web-optimised versions.
So, how can we download high-quality, low-filesize copies of the videos suitable for HTML5 use?
P-p-p-p-pick Up Some Python
We'll be using the excellent YouTube-DL - make sure you have the most recent version installed.
The Google Takeout from above contains a file called uploads.json - it has a list of every video you've uploaded and some associated metadata:
JSON
... ,{ "contentDetails" : { "videoId" : "2gIM9MzfaC8" }, "etag" : "\"mPrpS7Nrk6Ggi_P7VJ8-KsEOiIw/7fgl8GbhgRwxNU3aCz9jzUB_65M\"", "id" : "UUAEmywW2HASHP0MohSNIN0qHLpdeAxkQv", "kind" : "youtube#playlistItem", "snippet" : { "channelId" : "UCyC5lCspQ5sXZ9L3ZdEEF2Q", "channelTitle" : "Terence Eden", "description" : "Look at me walk to work!", "playlistId" : "UUyC5lCspQ5sXZ9L3ZdEEF2Q", "position" : 168, "publishedAt" : "2010-12-02T10:03:15.000Z", "resourceId" : { "kind" : "youtube#video", "videoId" : "2gIM9MzfaC8" }, "thumbnails" : { "default" : { "height" : 90, "url" : "https://i.ytimg.com/vi/2gIM9MzfaC8/default.jpg", "width" : 120 }, "high" : { "height" : 360, "url" : "https://i.ytimg.com/vi/2gIM9MzfaC8/hqdefault.jpg", "width" : 480 }, "medium" : { "height" : 180, "url" : "https://i.ytimg.com/vi/2gIM9MzfaC8/mqdefault.jpg", "width" : 320 } }, "title" : "Walking To Work In The Snow" }, "status" : { "privacyStatus" : "public" } }, { ...
So, we want to go through that JSON, download some web-friendly versions of the media, and save them.
This Python downloads a high resolution MP4 video and AAC audio - it then mixes them together. It will also download a slightly lower resolution WEBM file. It then grabs a screenshot and any subtitles which are present. Finally, a little HTML5 snippet is written.
Python 3
from __future__ import unicode_literals from datetime import datetime import youtube_dl import json import urllib import os # Read the JSON with open('uploads.json') as data_file: data = json.load(data_file) # Itterate through the JSON for video in data: videoId = video["contentDetails"]["videoId"] description = video["snippet"]["description"] publishedAt = video["snippet"]["publishedAt"] title = video["snippet"]["title"] status = video["status"]["privacyStatus"] # Create a date object based on the video's timestamp date_object = datetime.strptime(publishedAt,"%Y-%m-%dT%H:%M:%S.000Z") # Create a filepath and filename # /YYYYMMDD-HHMM/YYYYMMDD-HHMM_My Video_abc123 filepath = date_object.strftime('%Y%m%d-%H%M') filename = date_object.strftime('%Y%m%d') + "_" + title + "_" + videoId # YouTube Options ydl_opts = { # The highest quality MP4 should have the best resolution. # Best quality AAC audio - because that's the codec which will fit in an MP4 # A lower quality WEBM for HTML5 streaming 'format': 'bestvideo[ext=mp4]+bestaudio[acodec=aac],webm', 'audioformat' :'aac', 'merge_output_format' : 'mp4', # Don't create multiple copies of things 'nooverwrites' : 'true', # Some videos have subtitles 'writeautomaticsub' : 'true', 'writethumbnail' : 'true', # Make sure the filenames don't contain weird characters 'restrictfilenames' : 'true', # Add the correct extention for each filename 'outtmpl' : filepath + '/' + filename + '.%(ext)s', # If there is a problem, try again 'retries' : '5', # 'verbose' : 'true', } # Download the files with youtube_dl.YoutubeDL(ydl_opts) as ydl: if status == "private": # YouTube-DL won't download private videos print "Skipping private video " + videoId else: print "Downloading " + videoId + " to " + filename ydl.download(['http://www.youtube.com/watch?v='+videoId]) # Write an HTML5 snippet html = "<video poster=\""+filename+".jpg\" controls >\n" html += " <source src=\""+filename+".mp4\" type=\"video/mp4; codecs=mp4a.40.2, avc1.42001E\">\n" html += " <source src=\""+filename+".webm\" type=\"video/webm; codecs=vorbis, vp8.0\">\n" html += " <track src=\""+filename+".en.vtt\" kind=\"subtitles\" srclang=\"en\" label=\"English\">\n" html += "</video>" # Write the HTML with open(os.path.join(filepath, "video.html"), 'w') as html_file: html_file.write(html)
The files it downloads are significantly smaller than the original uploads - with no noticeable loss of quality. The combined size of the MP4 and WEBM are around half the size of the original files.

There is one major bug - occasionally the script will crap out with:
youtube_dl.utils.DownloadError: ERROR: content too short (expected 153471376 bytes and served 88079712)
This is a persistent error with YouTube-DL.
The script can be run again - it's smart enough to avoid re-downloading the videos.
And there you have it - a quick way to grab everything you've uploaded. It's missing a few things - view counts and comments, mostly - but it's good enough for re-hosting elsewhere.
This is what it looks like
This is what happens when you put that dash of HTML into a web-page:
I think there's a problem with the subtitle track - but it is not a finalised standard yet.
What links here from around this blog?